
Covariance in probability theory and statistics is a measure of the joint variability of two random variables.[1]
YouTube Encyclopedic
-
1/5Views:259 13244 03224 31446 5762 825
-
Covariance and the regression line | Regression | Probability and Statistics | Khan Academy
-
Covariance Example
-
Simple explanation: Covariance vs Correlation?
-
Lecture 21: Covariance and Correlation | Statistics 110
-
The importance of covariance
Transcription
What I want to do in this video is introduce you to the idea of the covariance between two random variables. And it's defined as the expected value of the distance-- or I guess the product of the distances of each random variable from their mean, or from their expected value. So let me just write that down. So I'll have X first, I'll do this in another color. So it's the expected value of random variable X minus the expected value of X. You could view this as the population mean of X times-- and then this is a random variable y-- so times the distance from Y to its expected value or the population mean of y. And if it doesn't make a lot of intuitive sense yet-- well, one, you could just always kind of think about what it's doing play around with some numbers here. But the reality is it's saying how much they vary together. So you always take an X and a y for each of the data points. Let's say you had the whole population. So every X and Y that kind of go together with each other that are coordinate you put into this. And what happens is-- let's say that X is above its mean when Y is below its mean. So let's say that in the population you had the point. So one instantiation of the random variables you sample once from the universe and you get X is equal to 1 and that Y is equal to-- let's say Y is equal to 3. And let's say that you knew ahead of time, that the expected value of X is 0. And let's say that the expected value of Y is equal to 4. So in this situation, what just happened? Now we don't know the entire covariance, we only have one sample here of this random variable. But what just happened here? We have one minus-- so we're just going to calculate, we're not going to calculate the entire expected value, I just want to calculate what happens when we do what's inside the expected value. We'll have 1 minus 0, so you'll have a 1 times a 3 minus 4, times a negative 1. So you're going to have 1 times negative 1, which is negative 1. And what is that telling us? Well, it's telling us at least for this sample, this one time that we sampled the random variables X and Y, X was above it's expected value when Y was below its expected value. And if we kept doing this, let's say for the entire population this happened, then it would make sense that they have a negative covariance. When one goes up, the other one goes down. When one goes down, the other one goes up. If they both go up together, they would have a positive variance or they both go down together. And the degree to which they do it together will tell you the magnitude of the covariance. Hopefully that gives you a little bit of intuition about what the covariance is trying to tell us. But the more important thing that I want to do in this video is to connect this formula. I want to connect to this definition of covariance to everything we've been doing with least squared regression. And really it's just kind of a fun math thing to do to show you all of these connections, and where, really, the definition of covariance really becomes useful. And I really do think it's motivated to a large degree by where it shows up in regressions. And this is all stuff that we've kind of seen before, you're just going to see it in a different way. So this whole video, I'm just going to rewrite this definition of covariance right over here. So this is going to be the same thing as the expected value of-- and I'm just going to multiply these two binomials in here. So the expected value of our random variable X times our random variable Y minus-- well, I'll just do the X first. So plus X times the negative expected value of Y. So I'll just say minus X times the expected value of Y. And that negative sign comes from this negative sign right over here. And then we have minus expected value of X times Y, just doing the distributive property twice, and then finally you have the negative expected value of X times a negative expected value of Y. And the negatives cancel out. And so you're just going to have plus the expected value of X times the expected value of Y. And of course, it's the expected value of this entire thing. Now let's see if we can rewrite this. Well the expected value of the sum of a bunch of random variables, or the sum and difference of a bunch of random variables, is just the sum or difference of their expected value. So this is going to be the same thing. And remember, expected value, in a lot of contexts, you could view it as just the arithmetic mean. Or, in a continuous distribution, you could view it as a probability weighted sum or probability weighted integral, either way. We've seen it before, I think. So let's rewrite this. So this is equal to the expected value of the random variables X and Y. X times Y. Trying to keep them color-coded for you. And then we have minus X times the expected value of Y. So then we're going to have minus the expected value of X times the expected value of Y. Stay with the right colors. Then you're going to have minus the expected value of this thing-- I'll close the parentheses-- of this thing right over here. Expected value of X times Y. I know this might look really confusing with all the embedded expected values. But one way to think about is the things that already have the expected values, you can view these as numbers. You've already used them as knowns. We're actually going to take them out of the expected value, because the expected value of an expected value is the same thing as the expected value. Actually let me write this over here, just remind ourselves. The expected value of X is just going to be the expected value of X. Think of it this way. You could view this as the population mean for the random variable. So that's just going to be a known, it's out there, it's in the universe. So the expected value of that is just going to be itself. If the population mean, or the expected value of X is 5-- this is like saying the expected value of 5. Well the expected value of 5 is going to be 5, which is the same thing as the expected value of X. Hopefully that makes sense, we're going to use that in a second. So we're almost done. We did the expected value of this and we have one term left. And then the final term, the expected value of this guy. And here, we can actually use a property right from the get go. I'll write it down. So the expected value of-- get some big brackets up-- of this thing right over here. Expected value of X times the expected value of Y. And let's see if we can simplify it right here. So this is just going to be the expected value of the product of these two random variables. I'll just leave that the way it is. So let me just-- the stuff that I'm going to leave the way it is I'm just going to freeze them. So the expected value of XY. Now what do we have over here? We have the expected value of X times-- once again, you can kind of view it if you go back to what we just said-- is this is just going to be a number, expected value of Y, so we can just bring this out. If this was the expected value of 3X, would be the same thing as 3 times the expected value of X. So we can rewrite this as negative expected value of Y times the expected value of X. You can kind of view this as we took it out of the expected value, we factored it out. So just like that. And then you have minus. Same thing over here. You can factor out this expected value of X. Minus the expected value of X times the expected value of Y. This is getting confusing with all the E's laying around. And then finally, the expected value of this thing, of two expected values, well that's just going to be the product of those two expected values. So that's just going to be plus-- I'll freeze this-- expected value of X times the expected value of Y. Now what do we have here? We have expected value of Y times the expected value of X. And then we are subtracting the expected value of X times the expected value of Y. These two things are the exact same thing. Right? So this is going to be-- and actually look at this. We're subtracting it twice and then we have one more. These are all the same thing. This is the expected value of Y times the expected value of X. This is the expected value of Y times the expected value of X, just written in a different order. And this is the expected value of Y times the expected value of X. We're subtracting it twice and then we're adding it. Or, one way to think about it is that this guy and that guy will cancel out. You could have also picked that guy and that guy. But what do we have left? We have the covariance of these two random variables. X and Y are equal to the expected value of-- I'll switch back to my colors just because this is the final result-- the expected value of X times the expected value of the product of XY minus-- what is this? The expected value of Y times the expected value of X. Now you can calculate these expected values if you know everything about the probability distribution or density functions for each of these random variables. Or if you had the entire population that you're sampling from, whenever you take an instantiation of these random variables. But let's say you just had a sample of these random variables. How could you estimate them? Well, if you were estimating it, the expected value, and let's say you just have a bunch of data points, a bunch of coordinates. And I think you'll start to see how this relates to what we do with regression. The expected value of X times Y, it can be approximated by the sample mean of the products of X and Y. This is going to be the sample mean of X and Y. You take each of your XY associations, take their product, and then take the mean of all of them. So that's going to be the product of X and Y. And then this thing right over here, the expected value of Y that can be approximated by the sample mean of Y, and the expected value of X can be approximated by the sample mean of X. So what can the covariance of two random variables be approximated by? What can it be approximated by? Well this right here is the mean of their product from your sample minus the mean of your sample Y's times the mean of your sample X's. And this should start looking familiar. This should look a little bit familiar, because what is this? This was the numerator. This right here is the numerator when we were trying to figure out the slope of the regression line. So when we tried to figure out the slope of the regression line, we had the-- let me just rewrite the formula here just to remind you-- it was literally the mean of the products of each of our data points, or the XY's, minus the mean of Y's times the mean of the X's. All of that over the mean the X squareds. And you could even view it as this, over the mean of the X times the X's. But I could just write the X squareds, over here, minus the mean of X squared. This is how we figured out the slope of our regression line. Or maybe a better way to think about it, if we assume in our regression line that the points that we have were a sample from an entire universe of possible points, then you could say that we are approximating the slope of our aggression line. And you might see this little hat notation in a lot of books. I don't want you to be confused. They are saying that you're approximating the population's regression line from a sample of it. Now, this right here-- so everything we've learned right now-- this right here is the covariance, or this is an estimate of the covariance of X and Y. Now what is this over here? Well, I just said, you could rewrite this very easily as-- this bottom part right here-- you could write as the mean of X times X-- that's the same thing as X squared-- minus the mean of X times the mean of X, right? That's what the mean of X squared is. Well, what's this? Well, you could view this as the covariance of X with X. But we've actually already seen this. And I've actually shown you many, many videos ago when we first learned about it what this is. The covariance of a random variable with itself is really just the variance of that random variable. And you could verify it for yourself. If you change this Y to an X, this becomes X minus the expected value of X times X minus expected value of X. Or that's the expected value of X minus the expected value of X squared. That's your definition of variance. So another way of thinking about the slope of our aggression line, it can be literally viewed as the covariance of our two random variables over the variance of X. Or you can kind of view it as the independent random variable. That right there is the slope of our regression line. Anyway, I thought that was interesting. And I wanted to make connections between things you see in different parts of statistics, and show you that they really are connected.
Definition
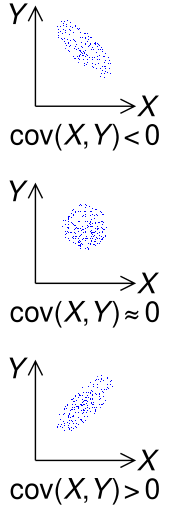
If greater values of one variable mainly correspond with greater values of the other variable, and the same holds for lesser values (that is, the variables tend to show similar behavior), the covariance is positive.[2] In the opposite case, when greater values of one variable mainly correspond to lesser values of the other (that is, the variables tend to show opposite behavior), the covariance is negative. The sign of the covariance, therefore, shows the tendency in the linear relationship between the variables. The magnitude of the covariance is the geometric mean of the variances that are in common for the two random variables. The correlation coefficient normalizes the covariance by dividing by the geometric mean of the total variances for the two random variables.
A distinction must be made between (1) the covariance of two random variables, which is a population parameter that can be seen as a property of the joint probability distribution, and (2) the sample covariance, which in addition to serving as a descriptor of the sample, also serves as an estimated value of the population parameter.
Mathematics
For two jointly distributed real-valued random variables and with finite second moments, the covariance is defined as the expected value (or mean) of the product of their deviations from their individual expected values:[3][4]: 119


![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {E} {{\big [}(X-\operatorname {E} [X])(Y-\operatorname {E} [Y]){\big ]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f98a8bf924edb41a8025b5ffaa1b255b4a6f48b9)
where is the expected value of , also known as the mean of . The covariance is also sometimes denoted or , in analogy to variance. By using the linearity property of expectations, this can be simplified to the expected value of their product minus the product of their expected values:
![{\displaystyle \operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)


![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)&=\operatorname {E} \left[\left(X-\operatorname {E} \left[X\right]\right)\left(Y-\operatorname {E} \left[Y\right]\right)\right]\\&=\operatorname {E} \left[XY-X\operatorname {E} \left[Y\right]-\operatorname {E} \left[X\right]Y+\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]\right]\\&=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]+\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]\\&=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right],\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b82a8c24b0063ffd95d8624f460acaaacb2a99b3)
The units of measurement of the covariance are those of times those of . By contrast, correlation coefficients, which depend on the covariance, are a dimensionless measure of linear dependence. (In fact, correlation coefficients can simply be understood as a normalized version of covariance.)

Complex random variables
The covariance between two complex random variables is defined as[4]: 119

![{\displaystyle \operatorname {cov} (Z,W)=\operatorname {E} \left[(Z-\operatorname {E} [Z]){\overline {(W-\operatorname {E} [W])}}\right]=\operatorname {E} \left[Z{\overline {W}}\right]-\operatorname {E} [Z]\operatorname {E} \left[{\overline {W}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc823fe25634365b1859a3ee206ca894203a9ee2)
Notice the complex conjugation of the second factor in the definition.
A related pseudo-covariance can also be defined.
Discrete random variables
If the (real) random variable pair can take on the values for , with equal probabilities , then the covariance can be equivalently written in terms of the means and as




![{\displaystyle \operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/639e8577c6faffc0471c7e123ead30970034e6d5)

It can also be equivalently expressed, without directly referring to the means, as[5]

More generally, if there are possible realizations of , namely but with possibly unequal probabilities for , then the covariance is



In the case where two discrete random variables and have a joint probability distribution, represented by elements corresponding to the joint probabilities of , the covariance is calculated using a double summation over the indices of the matrix:


![{\displaystyle \operatorname {cov} (X,Y)=\sum _{i=1}^{n}\sum _{j=1}^{n}p_{i,j}(x_{i}-E[X])(y_{j}-E[Y]).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b036eb4d41b2fb6291fda39c942f5720f4cf3329)
Examples
Consider 3 independent random variables and two constants .







Suppose that and have the following joint probability mass function,[6] in which the six central cells give the discrete joint probabilities of the six hypothetical realizations :


| x | ||||||
|---|---|---|---|---|---|---|
| 5 | 6 | 7 | ||||
| y | 8 | 0 | 0.4 | 0.1 | 0.5 | |
| 9 | 0.3 | 0 | 0.2 | 0.5 | ||
| 0.3 | 0.4 | 0.3 | 1 | |||


can take on three values (5, 6 and 7) while can take on two (8 and 9). Their means are and . Then,


![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)={}&\sigma _{XY}=\sum _{(x,y)\in S}f(x,y)\left(x-\mu _{X}\right)\left(y-\mu _{Y}\right)\\[4pt]={}&(0)(5-6)(8-8.5)+(0.4)(6-6)(8-8.5)+(0.1)(7-6)(8-8.5)+{}\\[4pt]&(0.3)(5-6)(9-8.5)+(0)(6-6)(9-8.5)+(0.2)(7-6)(9-8.5)\\[4pt]={}&{-0.1}\;.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a80fa4db641ca7ddd6f7a3fee8620eed15321a7)
Properties
Covariance with itself
The variance is a special case of the covariance in which the two variables are identical (that is, in which one variable has the same distribution as the other):[4]: 121

Covariance of linear combinations
If , , , and are real-valued random variables and are real-valued constants, then the following facts are a consequence of the definition of covariance:




For a sequence of random variables in real-valued, and constants , we have



Hoeffding's covariance identity
A useful identity to compute the covariance between two random variables is the Hoeffding's covariance identity:[7]




Random variables whose covariance is zero are called uncorrelated.[4]: 121 Similarly, the components of random vectors whose covariance matrix is zero in every entry outside the main diagonal are also called uncorrelated.
If and are independent random variables, then their covariance is zero.[4]: 123 [8] This follows because under independence,
![{\displaystyle \operatorname {E} [XY]=\operatorname {E} [X]\cdot \operatorname {E} [Y].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0c2870ec57051083bd6262aa4069a2500dfda44)
The converse, however, is not generally true. For example, let be uniformly distributed in and let . Clearly, and are not independent, but
![{\displaystyle [-1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51e3b7f14a6f70e614728c583409a0b9a8b9de01)

![{\displaystyle {\begin{aligned}\operatorname {cov} (X,Y)&=\operatorname {cov} \left(X,X^{2}\right)\\&=\operatorname {E} \left[X\cdot X^{2}\right]-\operatorname {E} [X]\cdot \operatorname {E} \left[X^{2}\right]\\&=\operatorname {E} \left[X^{3}\right]-\operatorname {E} [X]\operatorname {E} \left[X^{2}\right]\\&=0-0\cdot \operatorname {E} [X^{2}]\\&=0.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/19b6f2d636d5ef9ba85b6350e49222109a28d665)
In this case, the relationship between and is non-linear, while correlation and covariance are measures of linear dependence between two random variables. This example shows that if two random variables are uncorrelated, that does not in general imply that they are independent. However, if two variables are jointly normally distributed (but not if they are merely individually normally distributed), uncorrelatedness does imply independence.[9]
and whose covariance is positive are called positively correlated, which implies if then likely . Conversely, and with negative covariance are negatively correlated, and if then likely .
![{\displaystyle X>E[X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/166d8f9cb60b8835b723e34645e1f0c52a1852a5)
![{\displaystyle Y>E[Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02c197c6857af01266e2ed7c29485cad5a15118d)
![{\displaystyle Y<E[Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3eef3a2a3d98417f1d7684c3a6e530909c1c7c73)
Relationship to inner products
Many of the properties of covariance can be extracted elegantly by observing that it satisfies similar properties to those of an inner product:
- bilinear: for constants and and random variables
- symmetric:
- positive semi-definite: for all random variables , and implies that is constant almost surely.







In fact these properties imply that the covariance defines an inner product over the quotient vector space obtained by taking the subspace of random variables with finite second moment and identifying any two that differ by a constant. (This identification turns the positive semi-definiteness above into positive definiteness.) That quotient vector space is isomorphic to the subspace of random variables with finite second moment and mean zero; on that subspace, the covariance is exactly the L2 inner product of real-valued functions on the sample space.
As a result, for random variables with finite variance, the inequality

Proof: If , then it holds trivially. Otherwise, let random variable


Then we have
![{\displaystyle {\begin{aligned}0\leq \sigma ^{2}(Z)&=\operatorname {cov} \left(X-{\frac {\operatorname {cov} (X,Y)}{\sigma ^{2}(Y)}}Y,\;X-{\frac {\operatorname {cov} (X,Y)}{\sigma ^{2}(Y)}}Y\right)\\[12pt]&=\sigma ^{2}(X)-{\frac {(\operatorname {cov} (X,Y))^{2}}{\sigma ^{2}(Y)}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc8741ab12cb5943efe9d8dbfeb455517bc63347)
Calculating the sample covariance
The sample covariances among variables based on observations of each, drawn from an otherwise unobserved population, are given by the matrix with the entries



![{\displaystyle \textstyle {\overline {\mathbf {q} }}=\left[q_{jk}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb28ac928a2a379d039d27fb99d56dd21c1c027c)

which is an estimate of the covariance between variable and variable .


The sample mean and the sample covariance matrix are unbiased estimates of the mean and the covariance matrix of the random vector , a vector whose jth element is one of the random variables. The reason the sample covariance matrix has in the denominator rather than is essentially that the population mean is not known and is replaced by the sample mean . If the population mean is known, the analogous unbiased estimate is given by






- .

Generalizations
Auto-covariance matrix of real random vectors
For a vector of jointly distributed random variables with finite second moments, its auto-covariance matrix (also known as the variance–covariance matrix or simply the covariance matrix) (also denoted by or ) is defined as[10]: 335





![{\displaystyle {\begin{aligned}\operatorname {K} _{\mathbf {XX} }=\operatorname {cov} (\mathbf {X} ,\mathbf {X} )&=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {X} ]^{\mathrm {T} }.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/15725714f72a46ffb0686bafdb209260b842ac39)
Let be a random vector with covariance matrix Σ, and let A be a matrix that can act on on the left. The covariance matrix of the matrix-vector product A X is:

![{\displaystyle {\begin{aligned}\operatorname {cov} (\mathbf {AX} ,\mathbf {AX} )&=\operatorname {E} \left[\mathbf {AX(A} \mathbf {X)} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {AX} ]\operatorname {E} \left[(\mathbf {A} \mathbf {X} )^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {AXX} ^{\mathrm {T} }\mathbf {A} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {AX} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\mathbf {A} ^{\mathrm {T} }\right]\\&=\mathbf {A} \operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]\mathbf {A} ^{\mathrm {T} }-\mathbf {A} \operatorname {E} [\mathbf {X} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\right]\mathbf {A} ^{\mathrm {T} }\\&=\mathbf {A} \left(\operatorname {E} \left[\mathbf {XX} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} \left[\mathbf {X} ^{\mathrm {T} }\right]\right)\mathbf {A} ^{\mathrm {T} }\\&=\mathbf {A} \Sigma \mathbf {A} ^{\mathrm {T} }.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c1b2123c32a8acefc209a4f69d571ee1197a8c59)
This is a direct result of the linearity of expectation and is useful when applying a linear transformation, such as a whitening transformation, to a vector.
Cross-covariance matrix of real random vectors
For real random vectors and , the cross-covariance matrix is equal to[10]: 336



|
(Eq.2) |
![{\displaystyle {\begin{aligned}\operatorname {K} _{\mathbf {X} \mathbf {Y} }=\operatorname {cov} (\mathbf {X} ,\mathbf {Y} )&=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {Y} -\operatorname {E} [\mathbf {Y} ])^{\mathrm {T} }\right]\\&=\operatorname {E} \left[\mathbf {X} \mathbf {Y} ^{\mathrm {T} }\right]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {Y} ]^{\mathrm {T} }\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/99e6f5ef675f7bb826d04f206bd212d14632ab8c)
where is the transpose of the vector (or matrix) .


The -th element of this matrix is equal to the covariance between the i-th scalar component of and the j-th scalar component of . In particular, is the transpose of .




Cross-covariance sesquilinear form of random vectors in a real or complex Hilbert space
More generally let and , be Hilbert spaces over or with anti linear in the first variable, and let be resp. valued random variables. Then the covariance of and is the sesquilinear form on (anti linear in the first variable) given by









![{\displaystyle {\begin{aligned}\operatorname {K} _{X,Y}(h_{1},h_{2})=\operatorname {cov} (\mathbf {X} ,\mathbf {Y} )(h_{1},h_{2})&=\operatorname {E} \left[\langle h_{1},(\mathbf {X} -\operatorname {E} [\mathbf {X} ])\rangle _{1}\langle (\mathbf {Y} -\operatorname {E} [\mathbf {Y} ]),h_{2}\rangle _{2}\right]\\&=\operatorname {E} [\langle h_{1},\mathbf {X} \rangle _{1}\langle \mathbf {Y} ,h_{2}\rangle _{2}]-\operatorname {E} [\langle h,\mathbf {X} \rangle _{1}]\operatorname {E} [\langle \mathbf {Y} ,h_{2}\rangle _{2}]\\&=\langle h_{1},\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {Y} -\operatorname {E} [\mathbf {Y} ])^{\dagger }\right]h_{2}\rangle _{1}\\&=\langle h_{1},\left(\operatorname {E} [\mathbf {X} \mathbf {Y} ^{\dagger }]-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {Y} ]^{\dagger }\right)h_{2}\rangle _{1}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a5e62db23468fadd6a7f877ed44ede2bfbc07365)
Numerical computation
When , the equation is prone to catastrophic cancellation if and are not computed exactly and thus should be avoided in computer programs when the data has not been centered before.[11] Numerically stable algorithms should be preferred in this case.[12]
![{\displaystyle \operatorname {E} [XY]\approx \operatorname {E} [X]\operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5cc8091d0da21aa8f5a114797ba5113ddf534f69)
![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {E} \left[XY\right]-\operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdf56a30f7ff1be354713f144bfd02ba949a77f4)
![{\displaystyle \operatorname {E} \left[XY\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/128f7734bafe2a92d25d3df5fbb614e1d22b2e45)
![{\displaystyle \operatorname {E} \left[X\right]\operatorname {E} \left[Y\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f05701ae57cc8e32cd812037d7ba5d3d433021d4)
Comments
The covariance is sometimes called a measure of "linear dependence" between the two random variables. That does not mean the same thing as in the context of linear algebra (see linear dependence). When the covariance is normalized, one obtains the Pearson correlation coefficient, which gives the goodness of the fit for the best possible linear function describing the relation between the variables. In this sense covariance is a linear gauge of dependence.
Applications
In genetics and molecular biology
Covariance is an important measure in biology. Certain sequences of DNA are conserved more than others among species, and thus to study secondary and tertiary structures of proteins, or of RNA structures, sequences are compared in closely related species. If sequence changes are found or no changes at all are found in noncoding RNA (such as microRNA), sequences are found to be necessary for common structural motifs, such as an RNA loop. In genetics, covariance serves a basis for computation of Genetic Relationship Matrix (GRM) (aka kinship matrix), enabling inference on population structure from sample with no known close relatives as well as inference on estimation of heritability of complex traits.
In the theory of evolution and natural selection, the price equation describes how a genetic trait changes in frequency over time. The equation uses a covariance between a trait and fitness, to give a mathematical description of evolution and natural selection. It provides a way to understand the effects that gene transmission and natural selection have on the proportion of genes within each new generation of a population.[13][14]
In financial economics
Covariances play a key role in financial economics, especially in modern portfolio theory and in the capital asset pricing model. Covariances among various assets' returns are used to determine, under certain assumptions, the relative amounts of different assets that investors should (in a normative analysis) or are predicted to (in a positive analysis) choose to hold in a context of diversification.
In meteorological and oceanographic data assimilation
The covariance matrix is important in estimating the initial conditions required for running weather forecast models, a procedure known as data assimilation. The 'forecast error covariance matrix' is typically constructed between perturbations around a mean state (either a climatological or ensemble mean). The 'observation error covariance matrix' is constructed to represent the magnitude of combined observational errors (on the diagonal) and the correlated errors between measurements (off the diagonal). This is an example of its widespread application to Kalman filtering and more general state estimation for time-varying systems.
In micrometeorology
The eddy covariance technique is a key atmospherics measurement technique where the covariance between instantaneous deviation in vertical wind speed from the mean value and instantaneous deviation in gas concentration is the basis for calculating the vertical turbulent fluxes.
In signal processing
The covariance matrix is used to capture the spectral variability of a signal.[15]
In statistics and image processing
The covariance matrix is used in principal component analysis to reduce feature dimensionality in data preprocessing.
See also
References
- ^ Rice, John (2007). Mathematical Statistics and Data Analysis. Brooks/Cole Cengage Learning. p. 138. ISBN 9780534399429.
- ^ Weisstein, Eric W. "Covariance". MathWorld.
- ^ Oxford Dictionary of Statistics, Oxford University Press, 2002, p. 104.
- ^ a b c d e Park, Kun Il (2018). Fundamentals of Probability and Stochastic Processes with Applications to Communications. Springer. ISBN 9783319680743.
- ^ Yuli Zhang; Huaiyu Wu; Lei Cheng (June 2012). "Some new deformation formulas about variance and covariance". Proceedings of 4th International Conference on Modelling, Identification and Control(ICMIC2012). pp. 987–992.
- ^ "Covariance of X and Y | STAT 414/415". The Pennsylvania State University. Archived from the original on August 17, 2017. Retrieved August 4, 2019.
- ^ Papoulis (1991). Probability, Random Variables and Stochastic Processes. McGraw-Hill.
- ^ Siegrist, Kyle. "Covariance and Correlation". University of Alabama in Huntsville. Retrieved Oct 3, 2022.
- ^ Dekking, Michel, ed. (2005). A modern introduction to probability and statistics: understandig why and how. Springer texts in statistics. London [Heidelberg]: Springer. ISBN 978-1-85233-896-1.
- ^ a b Gubner, John A. (2006). Probability and Random Processes for Electrical and Computer Engineers. Cambridge University Press. ISBN 978-0-521-86470-1.
- ^ Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn., p. 232. Boston: Addison-Wesley.
- ^ Schubert, Erich; Gertz, Michael (2018). "Numerically stable parallel computation of (Co-)variance". Proceedings of the 30th International Conference on Scientific and Statistical Database Management. Bozen-Bolzano, Italy: ACM Press. pp. 1–12. doi:10.1145/3221269.3223036. ISBN 978-1-4503-6505-5. S2CID 49665540.
- ^ Price, George (1970). "Selection and covariance". Nature (journal). 227 (5257): 520–521. Bibcode:1970Natur.227..520P. doi:10.1038/227520a0. PMID 5428476. S2CID 4264723.
- ^ Harman, Oren (2020). "When science mirrors life: on the origins of the Price equation". Philosophical Transactions of the Royal Society B: Biological Sciences. 375 (1797). royalsocietypublishing.org: 1–7. doi:10.1098/rstb.2019.0352. PMC 7133509. PMID 32146891.
- ^ Sahidullah, Md.; Kinnunen, Tomi (March 2016). "Local spectral variability features for speaker verification". Digital Signal Processing. 50: 1–11. doi:10.1016/j.dsp.2015.10.011.