
In statistics, interval estimation is the use of sample data to estimate an interval of possible values of a parameter of interest. This is in contrast to point estimation, which gives a single value.[1]
The most prevalent forms of interval estimation are confidence intervals (a frequentist method) and credible intervals (a Bayesian method).[2] Less common forms include likelihood intervals, fiducial intervals, tolerance intervals, and prediction intervals. For a non-statistical method, interval estimates can be deduced from fuzzy logic.
YouTube Encyclopedic
-
1/5Views:499 969182 62067 160762 813430 038
-
How To Find The Z Score, Confidence Interval, and Margin of Error for a Population Mean
-
Estimation and Confidence Intervals
-
Confidence Interval in Statistics | Confidence Interval formula | Confidence Interval example
-
Confidence intervals and margin of error | AP Statistics | Khan Academy
-
Confidence Interval for a population mean - σ known
Transcription
Types of interval estimation
Confidence intervals
Confidence intervals are used to estimate the parameter of interest from a sampled data set, commonly the mean or standard deviation. A confidence interval states there is a 100γ% confidence that the parameter of interest is within a lower and upper bound. A common misconception of confidence intervals is 100γ% of the data set fits within or above/below the bounds, this is referred to as a tolerance interval, which is discussed below.
There are multiple methods used to build a confidence interval, the correct choice depends on the data being analyzed. For a normal distribution with a known variance, one uses the z-table to create an interval where a confidence level of 100γ% can be obtained centered around the sample mean from a data set of n measurements, . For a Binomial distribution, confidence intervals can be approximated using the Wald Approximate Method, Jeffreys interval, and Clopper-Pearson interval. The Jeffrey method can also be used to approximate intervals for a Poisson distribution.[3] If the underlying distribution is unknown, one can utilize bootstrapping to create bounds about the median of the data set.
Credible intervals
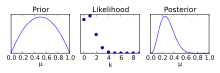
As opposed to a confidence interval, a credible interval requires a prior assumption, modifying the assumption utilizing a Bayes factor, and determining a posterior distribution. Utilizing the posterior distribution, one can determine a 100γ% probability the parameter of interest is included, as opposed to the confidence interval where one can be 100γ% confident that an estimate is included within an interval.[4]

While a prior assumption is helpful towards providing more data towards building an interval, it removes the objectivity of a confidence interval. A prior will be used to inform a posterior, if unchallenged this prior can lead to incorrect predictions.[5]
The credible interval's bounds are variable, unlike the confidence interval. There are multiple methods to determine where the correct upper and lower limits should be located. Common techniques to adjust the bounds of the interval include highest posterior density interval (HPDI), equal-tailed interval, or choosing the center the interval around the mean.
Less common forms
Likelihood-based
Utilizes the principles of a likelihood function to estimate the parameter of interest. Utilizing the likelihood-based method, confidence intervals can be found for exponential, Weibull, and lognormal means. Additionally, likelihood-based approaches can give confidence intervals for the standard deviation. It is also possible to create a prediction interval by combining the likelihood function and the future random variable.[3]
Fiducial
Fiducial inference utilizes a data set, carefully removes the noise and recovers a distribution estimator, Generalized Fiducial Distribution (GFD). Without the use of Bayes' Theorem, there is no assumption of a prior, much like confidence intervals.
Fiducial inference is a less common form of statistical inference. The founder, R.A. Fisher, who had been developing inverse probability methods, had his own questions about the validity of the process. While fiducial inference was developed in the early twentieth century, the late twentieth century believed that the method was inferior to the frequentist and Bayesian approaches but held an important place in historical context for statistical inference. However, modern-day approaches have generalized the fiducial interval into Generalized Fiducial Inference (GFI), which can be used to estimate discrete and continuous data sets.[6]
Tolerance
Tolerance intervals use collected data set population to obtain an interval, within tolerance limits, containing 100γ% values. Examples typically used to describe tolerance intervals include manufacturing. In this context, a percentage of an existing product set is evaluated to ensure that a percentage of the population is included within tolerance limits. When creating tolerance intervals, the bounds can be written in terms of an upper and lower tolerance limit, utilizing the sample mean, , and the sample standard deviation, s.

for two-sided intervals

for two-sided intervals
And in the case of one-sided intervals where the tolerance is required only above or below a critical value,


varies by distribution and the number of sides, i, in the interval estimate. In a normal distribution, can be expressed as [7]



Where,
is the critical value of the chi-square distribution utilizing degrees of freedom that is exceeded with probability .



is the critical values obtained from the normal distribution.

Prediction
A prediction interval estimates the interval containing future samples with some confidence, γ. Prediction intervals can be used for both Bayesian and frequentist contexts. These intervals are typically used in regression data sets, but prediction intervals are not used for extrapolation beyond the previous data's experimentally controlled parameters.[8]
Fuzzy logic
Fuzzy logic is used to handle decision-making in a non-binary fashion for artificial intelligence, medical decisions, and other fields. In general, it takes inputs, maps them through fuzzy inference systems, and produces an output decision. This process involves fuzzification, fuzzy logic rule evaluation, and defuzzification. When looking at fuzzy logic rule evaluation, membership functions convert our non-binary input information into tangible variables. These membership functions are essential to predict the uncertainty of the system.
One-sided vs. two-sided
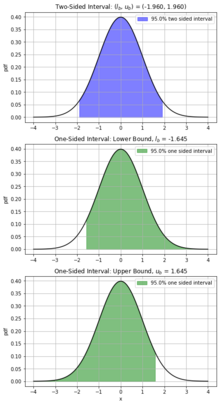
Two-sided intervals estimate a parameter of interest, Θ, with a level of confidence, γ, using a lower () and upper bound (). Examples may include estimating the average height of males in a geographic region or lengths of a particular desk made by a manufacturer. These cases tend to estimate the central value of a parameter. Typically, this is presented in a form similar to the equation below.



Differentiating from the two-sided interval, the one-sided interval utilizes a level of confidence, γ, to construct a minimum or maximum bound which predicts the parameter of interest to γ*100% probability. Typically, a one-sided interval is required when the estimate's minimum or maximum bound is not of interest. When concerned about the minimum predicted value of Θ, one is no longer required to find an upper bounds of the estimate, leading to a form reduced form of the two-sided.

As a result of removing the upper bound and maintaining the confidence, the lower-bound () will increase. Likewise, when concerned with finding only an upper bound of a parameter's estimate, the upper bound will decrease. A one-sided interval is a commonly found in material production's quality assurance, where an expected value of a material's strength, Θ, must be above a certain minimum value () with some confidence (100γ%). In this case, the manufacturer is not concerned with producing a product that is too strong, there is no upper-bound ().
Caution using and building estimates
When determining the significance of a parameter, it is best to understand the data and its collection methods. Before collecting data, an experiment should be planned such that the uncertainty of the data is sample variability, as opposed to a statistical bias.[9] After experimenting, a typical first step in creating interval estimates is plotting using various graphical methods. From this, one can determine the distribution of samples from the data set. Producing interval boundaries with incorrect assumptions based on distribution makes a prediction faulty.[10]
When interval estimates are reported, they should have a commonly held interpretation within and beyond the scientific community. Interval estimates derived from fuzzy logic have much more application-specific meanings.
In commonly occurring situations there should be sets of standard procedures that can be used, subject to the checking and validity of any required assumptions. This applies for both confidence intervals and credible intervals. However, in more novel situations there should be guidance on how interval estimates can be formulated. In this regard confidence intervals and credible intervals have a similar standing but there two differences. First, credible intervals can readily deal with prior information, while confidence intervals cannot. Secondly, confidence intervals are more flexible and can be used practically in more situations than credible intervals: one area where credible intervals suffer in comparison is in dealing with non-parametric models.
There should be ways of testing the performance of interval estimation procedures. This arises because many such procedures involve approximations of various kinds and there is a need to check that the actual performance of a procedure is close to what is claimed. The use of stochastic simulations makes this is straightforward in the case of confidence intervals, but it is somewhat more problematic for credible intervals where prior information needs to be taken properly into account. Checking of credible intervals can be done for situations representing no-prior-information but the check involves checking the long-run frequency properties of the procedures.
Severini discusses conditions under which credible intervals and confidence intervals will produce similar results, and also discusses both the coverage probabilities of credible intervals and the posterior probabilities associated with confidence intervals.[11]
In decision theory, which is a common approach to and justification for Bayesian statistics, interval estimation is not of direct interest. The outcome is a decision, not an interval estimate, and thus Bayesian decision theorists use a Bayes action: they minimize expected loss of a loss function with respect to the entire posterior distribution, not a specific interval.
Applications
Applications of confidence intervals are used to solve a variety of problems dealing with uncertainty. Katz (1975) proposes various challenges and benefits for utilizing interval estimates in legal proceedings.[12] For use in medical research, Altmen (1990) discusses the use of confidence intervals and guidelines towards using them.[13] In manufacturing, it is also common to find interval estimates estimating a product life, or to evaluate the tolerances of a product. Meeker and Escobar (1998) present methods to analyze reliability data under parametric and nonparametric estimation, including the prediction of future, random variables (prediction intervals).[14]
See also
- 68–95–99.7 rule
- Algorithmic inference
- Coverage probability
- Estimation statistics
- Induction (philosophy)
- Margin of error
- Multiple comparisons
- Philosophy of statistics
- Predictive inference
- Behrens–Fisher problem This has played an important role in the development of the theory behind applicable statistical methodologies.
References
- ^ Neyman, J. (1937). "Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability". Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences. 236 (767). The Royal Society: 333–380. Bibcode:1937RSPTA.236..333N. doi:10.1098/rsta.1937.0005. ISSN 0080-4614. JSTOR 91337. S2CID 19584450. Retrieved 2021-07-15.
- ^ Severini, Thomas A. (1991). "On the Relationship between Bayesian and Non-Bayesian Interval Estimates". Journal of the Royal Statistical Society, Series B (Methodological). 53 (3). Wiley: 611–618. doi:10.1111/j.2517-6161.1991.tb01849.x. ISSN 0035-9246.
- ^ a b Meeker, William Q.; Hahn, Gerald J.; Escobar, Luis A. (2017-03-27). Statistical Intervals: A Guide for Practitioners and Researchers. Wiley Series in Probability and Statistics (1 ed.). Wiley. doi:10.1002/9781118594841. ISBN 978-0-471-68717-7.
- ^ Hespanhol, Luiz; Vallio, Caio Sain; Costa, Lucíola Menezes; Saragiotto, Bruno T (2019-07-01). "Understanding and interpreting confidence and credible intervals around effect estimates". Brazilian Journal of Physical Therapy. 23 (4): 290–301. doi:10.1016/j.bjpt.2018.12.006. ISSN 1413-3555. PMC 6630113. PMID 30638956.
- ^ Lee, Peter M. (2012). Bayesian statistics: an introduction (4. ed., 1. publ ed.). Chichester: Wiley. ISBN 978-1-118-33257-3.
- ^ Hannig, Jan; Iyer, Hari; Lai, Randy C. S.; Lee, Thomas C. M. (2016-07-02). "Generalized Fiducial Inference: A Review and New Results". Journal of the American Statistical Association. 111 (515): 1346–1361. doi:10.1080/01621459.2016.1165102. ISSN 0162-1459.
- ^ Howe, W. G. (June 1969). "Two-Sided Tolerance Limits for Normal Populations, Some Improvements". Journal of the American Statistical Association. 64 (326): 610. doi:10.2307/2283644. ISSN 0162-1459.
- ^ Vardeman, Stephen B. (1992). "What about the Other Intervals?". The American Statistician. 46 (3): 193–197. doi:10.2307/2685212. ISSN 0003-1305.
- ^ Hahn, Gerald J.; Meeker, William Q. (1993). "Assumptions for Statistical Inference". The American Statistician. 47 (1): 1–11. doi:10.2307/2684774. ISSN 0003-1305.
- ^ Hahn, Gerald J.; Doganaksoy, Necip; Meeker, William Q. (2019-08-01). "Statistical Intervals, Not Statistical Significance". Significance. 16 (4): 20–22. doi:10.1111/j.1740-9713.2019.01298.x. ISSN 1740-9705.
- ^ Severini, Thomas A. (1993). "Bayesian Interval Estimates which are also Confidence Intervals". Journal of the Royal Statistical Society. Series B (Methodological). 55 (2): 533–540. ISSN 0035-9246.
- ^ Katz, Leo (1975). "Presentation of a Confidence Interval Estimate as Evidence in a Legal Proceeding". The American Statistician. 29 (4): 138–142. doi:10.2307/2683480. ISSN 0003-1305.
- ^ Altman, Douglas G., ed. (2011). Statistics with confidence: confidence intervals and statistical guidelines; [includes disk] (2. ed., [Nachdr.] ed.). London: BMJ Books. ISBN 978-0-7279-1375-3.
- ^ Meeker, William Q.; Escobar, Luis A. (1998). Statistical methods for reliability data. Wiley series in probability and statistics Applied probability and statistics section. New York Weinheim: Wiley. ISBN 978-0-471-14328-4.
Bibliography
- Kendall, M.G. and Stuart, A. (1973). The Advanced Theory of Statistics. Vol 2: Inference and Relationship (3rd Edition). Griffin, London.
- In the above Chapter 20 covers confidence intervals, while Chapter 21 covers fiducial intervals and Bayesian intervals and has discussion comparing the three approaches. Note that this work predates modern computationally intensive methodologies. In addition, Chapter 21 discusses the Behrens–Fisher problem.
- Meeker, W.Q., Hahn, G.J. and Escobar, L.A. (2017). Statistical Intervals: A Guide for Practitioners and Researchers (2nd Edition). John Wiley & Sons.
External links
- Fuzzy Math Introductions https://web.archive.org/web/20061205114153/http://blog.peltarion.com/2006/10/25/fuzzy-math-part-1-the-theory
- What is Fuzzy Logic? https://www.youtube.com/watch?v=__0nZuG4sTw
| Authority control databases: National |
|---|