

Landsmålsalfabetet («Алфавит шведских диалектов», швед. Svenska landsmålsalfabetet, англ. Swedish Dialect Alphabet), алфавит Лунделла[1] — фонетический алфавит, разработанный шведским лингвистом Юханом Августом Лунделлем для фонетической транскрипции диалектов шведского языка.
Алфавит основан на латинице со многими модификациями, например, буквами с различными вариантами крюка, и расширениями, среди которых греческие буквы γ и φ и кириллические буквы ы и л. При этом та или иная модификация символа соответствует одной и той же модификации обозначаемого звука[2]. Дополнительная артикуляция (например, огубленное произношение [k] перед гласным [u] в англ. cool) обозначается символом в нижнем индексе[3][4]: ku. Также используются диакритические знаки, отображающие суперсегментные единицы языка; в частности, макрон снизу указывает на долготу звука[5]. Обычно Landsmålsalfabetet использует строчные буквы в курсивном начертании, хотя более обобщённая транскрипция записывается прямым шрифтом[6][7].
Первоначально алфавит состоял из 89 букв[8], постепенно он был расширен более чем до 200 графем; стала возможна транскрипция и других языков, в том числе русского, китайского и диалектов английского[9].
Аналогичными системами для датского и норвежского языков являются Дания и Норвегия соответственно[10][11].
История и применение

В 1870-х годах в Уппсальском университете образовался ряд студенческих ассоциаций, целью которых являлась фиксация диалектов шведского языка, при этом в каждой из них употреблялась своя фонетическая запись. На Юхана Лунделля, тогда ещё студента, было возложено создание универсального алфавита. Возникшая в 1878 году система по сей день используется в лингвистике, преимущественно в Швеции и Финляндии[9].
Для алфавита 42 буквы были заимствованы из системы транскрипции, предложенной Карлом Якобом Сундевалем в работе Om phonetiska bokstafver («О фонетических буквах»; Стокгольм, 1856)[6][8][12].
В 1928 году Лунделлем была опубликована статья в журнале Studia Neophilologica, где подробно описывается его система и приводятся примеры её использования для шведского и русского языков[13]. В алфавите на тот момент насчитывалось 144 символа[6].
Алфавит используется шведским журналом <span lang="sv" style="font-style:italic;">Svenska landsmål och svenskt folkliv</span> («Шведские диалекты и фольклор»)[9], основанным Лунделлем[14], а также в словаре Ordbok över folkmålen i övre Dalarna («Словарь диалектов в Верхней Даларне»)[15][16]. Архив топонимов Шведского института языка и фольклора в Уппсале содержит картотеки с транскрипциями в Landsmålsalfabetet[17]. Системой пользовались языковеды, такие как Адольф Готтард Нурен[18] и Вильгельм Элиэль Викторинус Весман[19][16].
Производные системы
Многие символы транскрипций, использовавшихся шведским синологом Бернхардом Карлгреном в своей реконструкции среднекитайского языка, были взяты из Landsmålsalfabetet[10]. Первая версия его системы, Karlgren a, относится к 1915—1919 годам[20][21]; в 1922 году в транскрипцию были внесены изменения (Karlgren b), а в 1923 её упрощённый вариант, Karlgren c, был использован в его Analytic Dictionary (с англ. — «Аналитический словарь»). В опубликованном в 1954 году Compendium of Phonetics in Ancient and Archaic Chinese («Компендиум фонетики древнего и архаичного китайского») Карлгрен в последний раз модифицировал систему (Karlgren d). Ряд фонетических алфавитов, изобретённых другими синологами, в свою очередь основан на транскрипции Карлгрена[22].

Ordbok över Finlands svenska folkmål — словарь шведских диалектов, на которых говорят в Финляндии — применяет собственную транскрипцию с заимствованиями из Landsmålsalfabetet, в том числе ⱸ, ⱹ и ⱺ[23][16]. Словарь Ordbok över Sveriges dialekter («Словарь шведских диалектов») использует обобщённый вариант алфавита с урезанным набором символов[16], имеющих и заглавную форму. При этом в качестве заглавной a используется ![]() , в то время как прописная A соответствует строчной ɑ. ʃ в верхнем регистре выглядит как вытянутая S (
, в то время как прописная A соответствует строчной ɑ. ʃ в верхнем регистре выглядит как вытянутая S (![]() )[24].
)[24].
Кроме того, некоторые символы Landsmålsalfabetet переняты транскрипцией Фольке Хедблума[25].
Юникод
Некоторые символы диалектологии присутствуют в Юникоде начиная с его первой версии, так как входят в МФА или другие алфавиты. Ещё в 2001 году Консорциуму Юникода был представлен проект кодировки символов фонетической транскрипции[26]. С версией 5.1, вышедшей в 2008 году, три буквы алфавита, ⱸ, ⱹ и ⱺ, были включены в стандарт[27] для словаря Ordbok över Finlands svenska folkmål[16]. Символы находятся в блоке «Расширенная латиница — C» (англ. Latin Extended-C) под кодовыми позициями U+2C78, U+2C79 и U+2C7A соответственно, будучи ошибочно расположены в подблоке «Дополнения для Уральского фонетического алфавита» (англ. Additions for UPA)[28].
В 2008 году Майклом Эверсоном была подана заявка на включение 106 дополнительных букв для этого алфавита, а также символов ряда других фонетических транскрипций, не содержавшая, однако, доказательств их употребления[29]. По состоянию на момент выхода версии 14.0 стандарта предложение не принято, хотя определённые символы, в основном используемые в алфавите Teuthonista, закодированы по результатам других заявок (частично под кодовыми позициями, отличными от предусмотренных у Эверсона)[30][31][32]. Предложенный для блока «Фонетические расширения — A» (англ. Phonetic Extensions-A) кодовый диапазон 1E000—1E0FF на данный момент частично покрывается блоком «Дополнение к глаголице» (англ. Glagolitic Supplement)[33].
По причине отсутствия символов в стандарте кодировки существуют несовместимые с Юникодом шрифты, предназначенные для компьютерного набора текста в Landsmålsalfabetet, как, например, Dialekt Sve[34] и landsm_t[35]. Dialekt Uni совместим с Юникодом и отображает недостающие символы скандинавских диалектологий в Области для частного использования[34].
Галерея
-
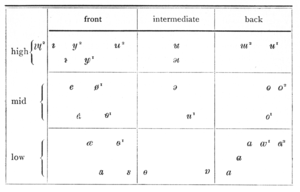
 Таблица согласных Landsmålsalfabetet 1879 года
Таблица согласных Landsmålsalfabetet 1879 года -
 Глифы шрифта Dialekt Uni в Области для частного использования Юникода (не все символы отсутствуют в стандарте)
Глифы шрифта Dialekt Uni в Области для частного использования Юникода (не все символы отсутствуют в стандарте) -
 Алфавит Сундеваля (1856). Заглавные и строчные буквы
Алфавит Сундеваля (1856). Заглавные и строчные буквы -

-
![Вариант печатной машины Imperial[en] с дополнительной клавиатурой для Landsmålsalfabetet](/wikipedia/commons/thumb/b/b7/Skrivmaskin_med_landsm%C3%A5lsalfabetet.jpg/240px-Skrivmaskin_med_landsm%C3%A5lsalfabetet.jpg) Вариант печатной машины Imperial с дополнительной клавиатурой для Landsmålsalfabetet
Вариант печатной машины Imperial с дополнительной клавиатурой для Landsmålsalfabetet


Примечания
- ↑ Блумфилд, Леонард. Глава V. Фонема // Язык = Language. — М.: Прогресс, 1968. — С. 85. — (Языковеды мира).
- ↑ Lundell, 1928, p. 5.
- ↑ Lundell, 1928, p. 11.
- ↑ Grip, 1901, p. 11.
- ↑ Lundell, 1928, pp. 14—15.
- ↑ 1 2 3 Lundell, 1928, p. 6.
- ↑ Lundell, 1878, p. 141.
- ↑ 1 2 Lundell, 1878, p. 14.
- ↑ 1 2 3 Lundell, 1928, p. 2.
- ↑ 1 2 Michaël Stenberg. TMH - QPSR Vol. 51 Phonetic transcriptions as a public service (англ.) (PDF). Королевский технологический институт. Дата обращения: 29 сентября 2019. Архивировано 12 июля 2019 года.
- ↑ Patrik Bye. Lydskrift (норв.) (html). uit.no. Университет Тромсё (29 июля 2003). Дата обращения: 29 сентября 2019. Архивировано из оригинала 4 марта 2016 года.
- ↑ Carl Jakob Sundevall. Om phonetiska bokstäver : [швед.] // Kungliga Svenska vetenskapsakademiens handlingar. — 1858. — Т. 1 (1855, 1856), вып. 1 (1855). — С. 25—92.
- ↑ Lundell, 1928.
- ↑ Svenska landsmål och svenskt folkliv. ISSN 0347-1837 (швед.). gustavadolfsakademien.se. Королевская академия Густава Адольфа. Дата обращения: 29 сентября 2019. Архивировано 26 августа 2019 года.
- ↑ Levander, Lars et al. Ordbok över folkmålen i övre Dalarna. — Uppsala: Dialekt- och folkminnesarkivet, 1961–.
- ↑ 1 2 3 4 5 Therese Leinonen, Klaas Ruppel, Erkki I. Kolehmainen, Caroline Sandström. Proposal to encode characters for Ordbok över Finlands svenska folkmål in the UCS (англ.) (PDF). unicode.org (26 января 2006). Дата обращения: 29 сентября 2019. Архивировано 14 июня 2019 года.
- ↑ Hur man tyder arkivkorten (швед.) (html). sprakochfolkminnen.se/. Шведский институт языка и фольклора. Дата обращения: 29 сентября 2019. Архивировано 29 сентября 2019 года.
- ↑ Noreen, Adolf. Vårt språk 1. — Lund: Gleerup, 1903.
- ↑ Wessman, V.E.V. Samling av ord ur östsvenska folkmål. — Helsinki: Svenska litteratursällskapet i Finland, 1930—1932.
- ↑ Bernhard Karlgren. Etudes sur la phonologie chinoise (фр.). — Leyde et Stockholm, 1915. Архивировано 20 апреля 2019 года.
- ↑ Bernhard Karlgren. Qualitative phonetics // A mandarin phonetic reader in the Pekinese dialect (англ.). — Stockholm: K.B. Norstedt & Söner, 1918. — P. 6—9.
- ↑ Branner, David Prager. Appendix II: Comparative transcriptions of rime table phonology // The Chinese Rime Tables: Linguistic Philosophy and Historical-Comparative Phonology (англ.) / John Benjamins. — Amsterdam, 2006. — Vol. 271. — P. 265–302. — (Current Issues in Linguistic Theory). — ISBN 978-90-272-4785-8.
- ↑ Hjälp (швед.). Институт исконных языков Финляндии. Дата обращения: 29 сентября 2019. Архивировано 8 июня 2020 года.
- ↑ Ordbok över Sveriges dialekter (швед.) / Gunnar Nyström. — 1991–2000. — Т. 1. — С. 9. Архивировано 23 мая 2019 года.
- ↑ Eriksson, 1961, pp. 138—139.
- ↑ Benny Brodda, Lars Törnqvist. Encoding of Swedish dialect transcripts (англ.) (PDF). unicode.org (10 марта 2001). Дата обращения: 29 сентября 2019. Архивировано 14 июня 2019 года.
- ↑ Unicode 5.1.0 (англ.). Юникод (4 апреля 2008). Дата обращения: 29 сентября 2019. Архивировано 10 апреля 2010 года.
- ↑ Latin Extended-C. Range: 2C60–2C7F (англ.) (PDF). Юникод. Дата обращения: 29 сентября 2019. Архивировано 24 октября 2019 года.
- ↑ Exploratory proposal to encode Germanicist, Nordicist, and other phonetic characters in the UCS (англ.) (PDF). unicode.org (27 ноября 2008). Дата обращения: 29 сентября 2019. Архивировано 15 июня 2019 года.
- ↑ Combining Diacritical Marks Extended. Range: 1AB0–1AFF (англ.) (PDF). Юникод. Дата обращения: 29 сентября 2019. Архивировано 29 октября 2019 года.
- ↑ Combining Diacritical Marks Supplement. Range: 1DC0–1DFF (англ.) (PDF). Юникод. Дата обращения: 29 сентября 2019. Архивировано 11 мая 2011 года.
- ↑ Latin Extended-E. Range: AB30–AB6F (англ.) (PDF). Юникод. Дата обращения: 29 сентября 2019. Архивировано 29 октября 2019 года.
- ↑ Glagolitic Supplement. Range: 1E000–1E02F (англ.) (PDF). Юникод. Дата обращения: 29 сентября 2019. Архивировано 29 октября 2019 года.
- ↑ 1 2 Dialekt (швед.). Дата обращения: 29 сентября 2019. Архивировано из оригинала 22 апреля 2016 года.
- ↑ Some fonts / Några typsnitt / teckensnitt (швед.). Дата обращения: 29 сентября 2019. Архивировано 1 мая 2019 года.
Литература
- Eriksson, Manne. Svensk ljudskrift 1878—1960. En översikt över det svenska landsmålsalfabetets utveckling och användning huvudsakligen i tidskriften Svenska Landsmål (швед.) / genom Dag Strömbäck. — Bilaga, 1961. — 184 p. — (Svenska landsmål och Svenskt folkliv).
- Grip, E. I. Ljudfysiologisk översikt. — In: Skuttungemålets ljudlära : [швед.] // Nyare bidrag till känedom om de Svenska landsmålen ock Svenskt folklif / genom J. A. Lundell. — Stockholm : Nordiska Bokhandeln, 1901. — С. 9—16.
- Kemp, J. Alan. Phonetic transcription: History // Encyclopedia of Language and Linguistics (англ.). — 2. — Elsevier Science, 2006. — Vol. 9. — P. 407. — ISBN 978-0080443652.
- Lundell, J. A. Det svenska landsmålsalfabetet : [швед.] // Nyare bidrag till känedom om de Svenska landsmålen ock Svenskt folklif / genom J. A. Lundell. — Stockholm : Samson & Wallin, 1878. — С. 11—158.
- Lundell, J. A. The Swedish dialect alphabet (англ.) // Studia Neophilologica : journal. — 1928. — Vol. 1, no. 1. — P. 1—17. — doi:10.1080/00393272808586721.
Ссылки
- Landsmålsalfabetet (швед.) (PDF). sprakochfolkminnen.se. Шведский институт языка и фольклора. Дата обращения: 29 сентября 2019.
- Uttalsbeteckningar enligt landsmålsalfabetet (швед.) (htm). sprakochfolkminnen.se. Шведский институт языка и фольклора. Дата обращения: 29 сентября 2019.
- «Landsmålsalfabetet», Nordisk familjebok, Т. 15 (1911) 1044, 1045—6, 1047—8 (швед.).
Обычно почти сразу, изредка в течении часа.