Для установки нажмите кнопочку Установить расширение. И это всё.
Исходный код расширения WIKI 2 регулярно проверяется специалистами Mozilla Foundation, Google и Apple. Вы также можете это сделать в любой момент.
Как перевоплотить Википедию
Хотите, чтобы Википедия всегда выглядела так профессионально и современно? Мы создали расширение для браузера. Оно совершенствует любую страницу энциклопедии, которую вы посетите, с помощью магических технологий WIKI 2.
Попробуйте — вы его можете удалить в любой момент.
Установить за 5 сек.
Да-да, но позже
4,5
Келли Слэйтон
Мои поздравления с отличным проектом... что за великолепная идея!
Александр Григорьевский
Я использую WIKI 2 каждый день и почти забыл как выглядит оригинальная Википедия.
Apache Spark (от англ.spark — искра, вспышка) — фреймворк с открытым исходным кодом для реализации распределённой обработки данных, входящий в экосистему проектов Hadoop. В отличие от классического обработчика из ядра Hadoop, реализующего двухуровневую концепцию MapReduce с хранением промежуточных данных на накопителях, Spark работает в парадигме резидентных вычислений — обрабатывает данные в оперативной памяти, благодаря чему позволяет получать значительный выигрыш в скорости работы для некоторых классов задач[7], в частности, возможность многократного доступа к загруженным в память пользовательским данным делает библиотеку привлекательной для алгоритмов машинного обучения[8].
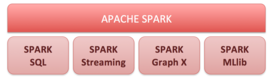
Проект предоставляет программные интерфейсы для языков Java, Scala, Python, R. Изначально написан на Scala, впоследствии добавлена существенная часть кода на Java для предоставления возможности написания программ непосредственно на Java. Состоит из ядра и нескольких расширений, таких как Spark SQL (позволяет выполнять SQL-запросы над данными), Spark Streaming (надстройка для обработки потоковых данных), Spark MLlib (набор библиотек машинного обучения), GraphX (предназначено для распределённой обработки графов). Может работать как в среде кластера Hadoop под управлением YARN, так и без компонентов ядра Hadoop, поддерживает несколько распределённых систем хранения — HDFS, OpenStack Swift, NoSQL-СУБД Cassandra, Amazon S3.
Ключевой автор — румынско-канадский учёный в области информатики Матей Захария (англ.Matei Zaharia), начал работу над проектом в 2009 году, будучи аспирантом Университета Калифорнии в Беркли. В 2010 году проект опубликован под лицензией BSD, в 2013 году передан фонду Apache и переведён на лицензию Apache 2.0, в 2014 году принят в число проектов верхнего уровня Apache. В 2022 году проект получил ежегодную премию SIGMOD в номинации «Системы»[9].
Энциклопедичный YouTube
1/5
Просмотров:
4 690
728
746
14 328
7 152
Пайплайн машинного обучения на Apache Spark / Павел Клеменков (Rambler&Co)
Использование Spark для машинного обучения
Практический курс «MLSP: Машинное обучение в Apache Spark» - «Школа Больших Данных» Москва
Что такое Apache Spark
DATALEARN | DE - 101 | МОДУЛЬ 7-2 ЧТО ТАКОЕ APACHE SPARK
Х. Карау, Э. Конвински, П. Венделл, М. Захария. Изучаем Spark. Молниеносный анализ данных = Learning Spark: Lightning-Fast Big Data Analytics (O’Reilly, 2015). — ДМК Пресс, 2015. — 304 с. — ISBN 978-5-97060-323-9.
С. Риза, У. Лезерсон, Ш. Оуэн, Д. Уиллс. Spark для профессионалов: современные паттерны обработки больших данных = Advanced Analytics with Spark. Patterns for Learning from Data at Scale (O’Reilly, 2015). — Питер, 2017. — 272 с. — ISBN 978-5-496-02401-3.
Уоррен Р., Карау Х. Эффективный Spark. Масштабирование и оптимизация = High Performance Spark. Best Practices for Scaling and Optimizing Apache Spark. — Питер, 2018. — 352 с. — ISBN 978-5-4461-0705-6.