
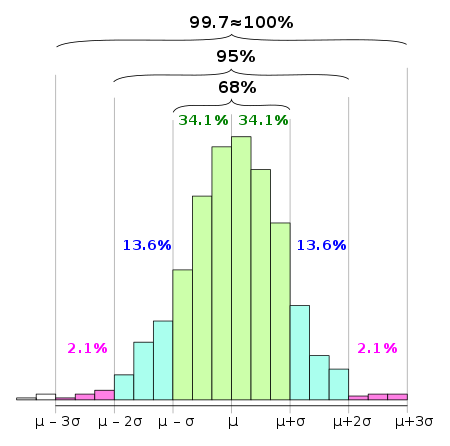

En estadística, la regla 68-95-99.7, también conocida como regla empírica, es una abreviatura utilizada para recordar el porcentaje de valores que se encuentran dentro de una banda alrededor de la media en una distribución normal con un ancho de dos, cuatro y seis veces la desviación típica, respectivamente. Más exactamente, el 68.27 %, el 95.45 % y el 99.73 % de los valores se encuentran dentro de bandas con semiancho de una, dos y tres veces la desviación típica respecto a la media.
En notación matemática, estos hechos se pueden expresar de la siguiente manera, siendo Χ es una observación de una variable aleatoria normalmente distribuida, μ es la media aritmética de la distribución y σ es su desviación estándar:

En las ciencias empíricas, la también llamada "regla del pulgar de las tres sigmas" denota un criterio heurístico convencional que considera que casi todos los valores de una muestra se encuentran dentro de tres desviaciones estándar de la media, y que por lo tanto en la práctica es útil tratar el 99.7 % de probabilidad como certeza.[1] La utilidad de esta práctica depende significativamente de la pregunta que se esté considerando. En las ciencias sociales, un resultado puede considerarse significativo si su intervalo de confianza del efecto analizado es del orden de dos sigma (95 %), mientras que en física de partículas, existe la convención de que un determinado nuevo efecto debe constatarse en un intervalo de confianza de cinco sigmas (99.99994 %) para ser calificado como un hecho cierto y considerarse un descubrimiento.
La regla del pulgar de las tres sigmas se relaciona con un resultado también conocido como la regla de las tres sigma, que establece que incluso para las variables de distribución no normal, al menos el 88.8 % de los casos deben encajar correctamente en intervalos de tres sigma. Este principio se deduce de la Desigualdad de Chebyshov. Para distribuciones unimodales, la probabilidad de estar dentro del intervalo es de al menos el 95 %. Pueden darse ciertas suposiciones para una distribución que obliguen a que esta probabilidad sea al menos del 98 %.[2]
Demostración
Tenemos que
- ,

haciendo el cambio de variables , obtenemos

- ,

y esta integral es independiente de y . Sólo necesitamos calcular la integral en los casos .




Función de distribución acumulada

Estos valores numéricos "68 %, 95 %, 99.7 %" provienen de la función de distribución acumulada de la distribución normal.
El intervalo de predicción para cualquier unidad tipificada z corresponde numéricamente a (1 − (1 − Φμ,σ2 (z)) · 2).
Por ejemplo, Φ(2) ≈ 0.9772, o Pr(X ≤ μ + 2σ) ≈ 0.9772, correspondiente a un intervalo de predicción de (1 - (1 - 0.97725) · 2) = 0.9545 = 95.45%.
Debe tenerse en cuenta que esta fórmula es una aproximación, puesto que los intervalos no son necesariamente simétricos, y aquí se ha calculado simplemente dos veces la probabilidad de que una observación sea menor que μ + 2σ. Para calcular la probabilidad de que una observación se encuentre dentro de dos desviaciones estándar de la media, el procedimiento exacto (con pequeñas diferencias debidas al redondeo) es:

Esto se relaciona con los intervalos de confianza como se utilizan en las estadísticas: tiene aproximadamente un intervalo de confianza del 95% cuando es el promedio de una muestra de tamaño .



Pruebas de normalidad
La "regla 68-95-99.7" se usa a menudo para obtener rápidamente una estimación de probabilidad aproximada de alguna muestra, conocida su desviación estándar, si se supone que la población es normal. También se usa como una prueba simple para determinar si un valor es atípico suponiendo que la población es normal, y como prueba de normalidad si la población es potencialmente no normal.
Para relacionar una muestra con su desviación típica, primero se calcula su desviación a partir de sus errores o residuos, dependiendo de si se conoce la media de la población o solo se estima. El siguiente paso es regularizar porcentualmente los resultados (dividiéndolos por la desviación estándar de la población), si se conocen los parámetros de la población, o sometiéndolos a studentización (dividiéndolos por una estimación de la desviación estándar), si los parámetros son desconocidos y solo se estiman.
Para usarlo como prueba de la normalidad de la muestra o de que se compone de valores atípicos, se calcula el tamaño de las desviaciones en términos de desviaciones estándar y se compara con la frecuencia esperada. Dado un conjunto de muestras, se pueden calcular los residuos studentizados y compararlos con las frecuencias esperadas: los puntos que quedan más allá de 3 desviaciones estándar de la norma son probablemente valores atípicos (a menos que el tamaño de la muestra sea significativamente grande, por lo que podría tratarse de una muestra de este extremo de la población), y si hay muchos puntos a más de 3 desviaciones estándar de la norma, es probable que haya una razón para cuestionar la normalidad asumida de la distribución. Este criterio es cada vez más sólido a medida que el procedimiento se extiende a 4 o a más desviaciones típicas.
Se puede calcular de forma más precisa, aproximando el número de valores extremos esperables de una magnitud dada o mayor mediante una distribución de Poisson, pero simplemente, si aparecen múltiples valores por fuera de la banda de 4 sigma en una muestra de tamaño 1000, entonces se dispone de una razón sólida para considerar que estos valores son atípicos o para preguntarse acerca de la presunta normalidad de la distribución considerada.
Por ejemplo, un evento 6σ corresponde a una probabilidad de aproximadamente dos partes en mil millones. Por ejemplo, si se considera que los eventos ocurren diariamente, esto correspondería a un evento esperado cada 1,4 millones de años. Esto da una aproximación muy útil: si se es testigo de un suceso 6σ en datos diarios y ha pasado significativamente menos de 1 millón de años, entonces una distribución normal muy probablemente no proporciona un buen modelo para la magnitud o frecuencia de grandes desviaciones contempladas en este caso.
En El cisne negro, Nassim Taleb da el ejemplo de los modelos de riesgo según los cuales la caída bursátil del Lunes Negro correspondería a un evento 36-σ: la ocurrencia de tal evento debería sugerir instantáneamente que el modelo es defectuoso, es decir, que el proceso en consideración no está modelado satisfactoriamente por una distribución normal. Los modelos refinados deben considerarse, por ejemplo, por la introducción de la volatilidad estocástica. En tales análisis, es importante estar al tanto del problema de la falacia del apostador, que establece que una sola observación de un evento raro no contradice que el evento sea de hecho raro. Es la observación de una pluralidad de eventos supuestamente raros lo que cada vez más hace reconsiderar la hipótesis de que son raros, es decir, la validez del modelo asumido. Un modelo adecuado de este proceso de pérdida gradual de confianza en una hipótesis implicaría la estimación de la probabilidad a priori no solo para la hipótesis en sí, sino para todas las hipótesis alternativas posibles. Por esta razón, el contraste de hipótesis no solo funciona confirmando una hipótesis que se considere probable, sino también refutando hipótesis consideradas improbables.
Tabla de valores numéricos
Debido a las colas exponenciales de la distribución normal, las probabilidades de desviaciones más altas disminuyen muy rápidamente. A partir de las reglas para datos normalmente distribuidos para un evento diario:
| Rango | Fracción esperada de la población dentro del rango | Frecuencia aproximada esperada fuera del rango | Frecuencia aproximada para un evento diario |
|---|---|---|---|
| μ ± 0.5σ | 0.382924922548026 | 2 en 3 | Cuatro o cinco veces a la semana |
| μ ± σ | 0.682689492137086 | 1 en 3 | Dos veces a la semana |
| μ ± 1.5σ | 0.866385597462284 | 1 en 7 | Semanalmente |
| μ ± 2σ | 0.954499736103642 | 1 en 22 | Cada tres semanas |
| μ ± 2.5σ | 0.987580669348448 | 1 en 81 | Trimestralmente |
| μ ± 3σ | 0.997300203936740 | 1 en 370 | Anualmente |
| μ ± 3.5σ | 0.999534741841929 | 1 en 2149 | Cada 6 años |
| μ ± 4σ | 0.999936657516334 | 1 en 15 787 | Cada 43 años (dos veces en la vida) |
| μ ± 4.5σ | 0.999993204653751 | 1 en 147 160 | Cada 403 años (una vez en la edad moderna) |
| μ ± 5σ | 0.999999426696856 | 1 en 1 744 278 | Cada 4776 años (una vez en la historia documentada) |
| μ ± 5.5σ | 0.999999962020875 | 1 en 26 330 254 | Cada 72 090 años (tres veces en la historia del ser humano moderno) |
| μ ± 6σ | 0.999999998026825 | 1 en 506 797 346 | Cada 1.38 millones de años (dos veces en la historia del ser humano) |
| μ ± 6.5σ | 0.999999999919680 | 1 en 12 450 197 393 | Cada 34 millones de años (dos veces desde la extinción de los dinosaurios) |
| μ ± 7σ | 0.999999999997440 | 1 en 390 682 215 445 | Cada 1070 millones de años (cuatro veces en la historia de la Tierra) |
| μ ± xσ | 1 en | Cada días |


siendo la "fracción esperada de la población dentro del rango" en el intervalo dado.
Véase también
Referencias
- ↑ Este uso de la "regla de las tres sigmas" se hizo común en la década de 2000. Es citado por ejemplo en Schaum's Outline of Business Statistics. McGraw Hill Professional. 2003. p. 359, y en Grafarend, Erik W. (2006). Linear and Nonlinear Models: Fixed Effects, Random Effects, and Mixed Models. Walter de Gruyter. p. 553.
- ↑ Véase:
- Wheeler, D. J.; Chambers, D. S. (1992). Understanding Statistical Process Control. SPC Press.
- Czitrom, Veronica; Spagon, Patrick D. (1997). Statistical Case Studies for Industrial Process Improvement. SIAM. p. 342.
- Pukelsheim, F. (1994). «The Three Sigma Rule». American Statistician 48: 88-91. JSTOR 2684253.
Enlaces externos
- "The Normal Distribution" por Balasubramanian Narasimhan
- "Cálculo del porcentaje de x dentro de intervalos de sigma en WolframAlpha
| Control de autoridades |
|
|---|
 Datos: Q847822
Datos: Q847822 Multimedia: 68–95–99.7 rule / Q847822
Multimedia: 68–95–99.7 rule / Q847822