
La estructura genética es la organización de elementos de secuencia especializados dentro de un gen. Los genes contienen la información necesaria para que las células vivas sobrevivan y se reproduzcan.[1][2] En la mayoría de los organismos, los genes están hechos de ADN, donde la secuencia particular de ADN determina la función del gen. Un gen se transcribe (copia) del ADN al ARN, que puede ser no codificante (ncRNA) con una función directa, o un mensajero intermedio (ARNm) que luego se traduce en proteína. Cada uno de estos pasos está controlado por elementos de secuencia específicos, o regiones, dentro del gen. Por lo tanto, cada gen requiere múltiples elementos de secuencia para ser funcional. Esto incluye la secuencia que realmente codifica la proteína funcional o ncRNA, así como múltiples regiones de secuencia reguladora. Estas regiones pueden ser tan cortas como unos pocos pares de bases, hasta muchos miles de pares de bases de largo.
Gran parte de la estructura genética es ampliamente similar entre eucariotas y procariotas. Estos elementos comunes resultan en gran medida de la ascendencia compartida de la vida celular en los organismos hace más de 2 mil millones de años.[3] Las diferencias clave en la estructura génica entre eucariotas y procariotas reflejan su maquinaria divergente de transcripción y traducción.[4][5] Comprender la estructura de los genes es la base para comprender la anotación, la expresión y la función de los genes.[6]
Características comunes
Las estructuras de los genes eucariotas y procariotas involucran varios elementos de secuencia anidados. Cada elemento tiene una función específica en el proceso de múltiples pasos de la expresión génica. Las secuencias y longitudes de estos elementos varían, pero las mismas funciones generales están presentes en la mayoría de los genes.[2] Aunque el ADN es una molécula bicatenaria, típicamente solo una de las cadenas codifica información que la ARN polimerasa lee para producir ARNm codificante de proteínas o ARN no codificante. Este 'sentido' o hebra 'codificación', se ejecuta en el 5' a 3' dirección, donde los números se refieren a los átomos de carbono de la cadena principal de azúcar ribosa. El marco de lectura abierto (ORF, del inglés open reading frame) de un gen, por lo tanto, generalmente se representa como una flecha que indica la dirección en la que se lee la cadena sensorial.[7]
Las secuencias reguladoras se encuentran en las extremidades de los genes. Estas regiones de secuencia pueden estar al lado de la región transcrita (el promotor) o separadas por muchas kilobases (potenciadores y silenciadores).[8] El promotor está ubicado en el extremo 5 'del gen y está compuesto por una secuencia promotora central y una secuencia promotora proximal. El promotor central marca el sitio de inicio para la transcripción uniendo la ARN polimerasa y otras proteínas necesarias para copiar ADN en ARN. La región promotora proximal se une a factores de transcripción que modifican la afinidad del promotor central por la ARN polimerasa.[9][10] Los genes pueden estar regulados por múltiples secuencias potenciadoras y silenciadoras que modifican aún más la actividad de los promotores mediante la unión de proteínas activadoras o represoras.[11][12] Potenciadores y silenciadores pueden ubicarse distantemente del gen, a miles de pares de bases de distancia. La unión de diferentes factores de transcripción, por lo tanto, regula la velocidad de iniciación de la transcripción en diferentes momentos y en diferentes células.[13]
Los elementos reguladores pueden superponerse entre sí, con una sección de ADN capaz de interactuar con muchos activadores y represores competidores, así como con la ARN polimerasa. Por ejemplo, algunas proteínas represoras pueden unirse al promotor central para evitar la unión de la polimerasa.[14] Para los genes con múltiples secuencias reguladoras, la tasa de transcripción es el producto de todos los elementos combinados.[15] La unión de activadores y represores a múltiples secuencias reguladoras tiene un efecto cooperativo en el inicio de la transcripción.[16]
Aunque todos los organismos usan activadores y represores transcripcionales, se dice que los genes eucariotas están 'desactivados por defecto', mientras que los genes procariotas están 'activados por defecto'.[5] El promotor central de los genes eucariotas generalmente requiere una activación adicional por parte de los elementos promotores para que se produzca la expresión. El promotor central de los genes procariotas, por el contrario, es suficiente para una expresión fuerte y está regulado por represores.
Se produce una capa adicional de regulación para los genes que codifican proteínas después de que el ARNm ha sido procesado para prepararlo para la traducción a la proteína. Solo la región entre los codones de inicio y parada codifica el producto proteico final. Las regiones no traducidas flanqueantes (UTR, del inglés flanking untranslated regions) contienen secuencias reguladoras adicionales.[17] El 3 'UTR contiene una secuencia de terminación, que marca el punto final para la transcripción y libera la ARN polimerasa.[18] El 5 'UTR se une al ribosoma, que traduce la región codificante de la proteína en una cadena de aminoácidos que se pliegan para formar el producto proteico final. En el caso de genes para ARN no codificantes, el ARN no se traduce, sino que se pliega para ser directamente funcional.[19][20]

Eucariotas
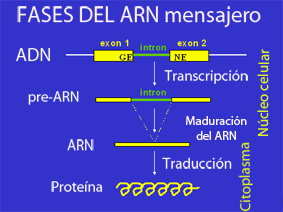
La estructura de los genes eucariotas incluye características que no se encuentran en los procariotas. La mayoría de estos se relacionan con la modificación postranscripcional de pre-ARNm para producir ARNm maduro listo para la traducción en proteína. Los genes eucariotas suelen tener más elementos reguladores para controlar la expresión génica en comparación con los procariotas.[5] Esto es particularmente cierto en eucariotas multicelulares, humanos, por ejemplo, donde la expresión génica varía ampliamente entre los diferentes tejidos.[11]
Una característica clave de la estructura de los genes eucariotas es que sus transcripciones generalmente se subdividen en regiones de exón e intrón. Las regiones de exón se retienen en la molécula de ARNm madura final, mientras que las regiones de intrón se empalman (se extirpan) durante el procesamiento post-transcripcional.[22] De hecho, las regiones intrónicas de un gen pueden ser considerablemente más largas que las regiones exónicas. Una vez empalmados, los exones forman una única región continua que codifica proteínas, y los límites de empalme no son detectables. El procesamiento post-transcripcional eucariota también agrega una tapa de 5' al comienzo del ARNm y una cola de poliadenosina al final del ARNm. Estas adiciones estabilizan el ARNm y dirigen su transporte desde el núcleo al citoplasma, aunque ninguna de estas características está codificada directamente en la estructura de un gen.[17]
Procariotas
La organización general de los genes procariotas es marcadamente diferente de la de los eucariotas. La diferencia más obvia es que los marcos abiertos de lectura (ORF) procarióticos a menudo se agrupan en un operón policistrónico bajo el control de un conjunto compartido de secuencias reguladoras. Todos estos ORF se transcriben en el mismo ARNm y, por lo tanto, se regulan conjuntamente y a menudo cumplen funciones relacionadas.[23][24] Cada ORF generalmente tiene su propio sitio de unión al ribosoma (RBS) de modo que los ribosomas traducen simultáneamente los ORF en el mismo ARNm. Algunos operones también muestran acoplamiento traduccional, donde las tasas de traducción de múltiples ORF dentro de un operón están vinculadas.[25] Esto puede ocurrir cuando el ribosoma permanece unido al final de un ORF y simplemente se transloca al siguiente sin la necesidad de un nuevo RBS.[26] El acoplamiento traduccional también se observa cuando la traducción de un ORF afecta la accesibilidad del siguiente RBS a través de cambios en la estructura secundaria del ARN.[27] Tener múltiples ORF en un único ARNm solo es posible en procariotas porque su transcripción y traducción tienen lugar al mismo tiempo y en la misma ubicación subcelular.[28]
La secuencia del operador al lado del promotor es el principal elemento regulador en los procariotas. Las proteínas represoras unidas a la secuencia del operador obstruyen físicamente la enzima ARN polimerasa, evitando la transcripción.[29][30] Los riboswitches son otra secuencia reguladora importante comúnmente presente en las UTR procariotas. Estas secuencias cambian entre estructuras secundarias alternativas en el ARN dependiendo de la concentración de metabolitos clave. Las estructuras secundarias bloquean o revelan regiones de secuencia importantes, como los RBS. Los intrones son extremadamente raros en los procariotas y, por lo tanto, no juegan un papel importante en la regulación del gen procariota.[31]
Referencias
- ↑ Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Raff, Martin; Roberts, Keith; Walter, Peter (2002). «How Genetic Switches Work». Molecular Biology of the Cell (4 edición).
- ↑ a b Polyak, Kornelia; Meyerson, Matthew (2003). «Overview: Gene Structure». Cancer Medicine (6 edición). BC Decker.
- ↑ Werner, Finn; Grohmann, Dina (2011). «Evolution of multisubunit RNA polymerases in the three domains of life». Nature Reviews Microbiology 9 (2): 85-98. ISSN 1740-1526. PMID 21233849. doi:10.1038/nrmicro2507.
- ↑ Kozak, Marilyn (1999). «Initiation of translation in prokaryotes and eukaryotes». Gene 234 (2): 187-208. ISSN 0378-1119. PMID 10395892. doi:10.1016/S0378-1119(99)00210-3.
- ↑ a b c Struhl, Kevin (1999). «Fundamentally Different Logic of Gene Regulation in Eukaryotes and Prokaryotes». Cell 98 (1): 1-4. ISSN 0092-8674. PMID 10412974. doi:10.1016/S0092-8674(00)80599-1.
- ↑ Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Raff, Martin; Roberts, Keith; Walter, Peter (2002). Molecular Biology of the Cell (Fourth edición). New York: Garland Science. ISBN 978-0-8153-3218-3.
- ↑ Lu, G. (2004). «Vector NTI, a balanced all-in-one sequence analysis suite». Briefings in Bioinformatics 5 (4): 378-388. ISSN 1467-5463. PMID 15606974. doi:10.1093/bib/5.4.378.
- ↑ Wiper-Bergeron, Nadine; Skerjanc, Ilona S. (2009). Transcription and the Control of Gene Expression. Humana Press. pp. 33-49. ISBN 978-1-59745-440-7. doi:10.1007/978-1-59745-440-7_2.
- ↑ Thomas, Mary C.; Chiang, Cheng-Ming (2008). «The General Transcription Machinery and General Cofactors». Critical Reviews in Biochemistry and Molecular Biology 41 (3): 105-178. ISSN 1040-9238. PMID 16858867. doi:10.1080/10409230600648736.
- ↑ Juven-Gershon, Tamar; Hsu, Jer-Yuan; Theisen, Joshua WM; Kadonaga, James T (2008). «The RNA polymerase II core promoter — the gateway to transcription». Current Opinion in Cell Biology 20 (3): 253-259. ISSN 0955-0674. PMC 2586601. PMID 18436437. doi:10.1016/j.ceb.2008.03.003.
- ↑ a b Maston, Glenn A.; Evans, Sara K.; Green, Michael R. (2006). «Transcriptional Regulatory Elements in the Human Genome». Annual Review of Genomics and Human Genetics 7 (1): 29-59. ISSN 1527-8204. PMID 16719718. doi:10.1146/annurev.genom.7.080505.115623.
- ↑ Pennacchio, L. A.; Bickmore, W.; Dean, A.; Nobrega, M. A.; Bejerano, G. (2013). «Enhancers: Five essential questions». Nature Reviews Genetics 14 (4): 288-95. PMC 4445073. PMID 23503198. doi:10.1038/nrg3458.
- ↑ Maston, G. A.; Evans, S. K.; Green, M. R. (2006). «Transcriptional Regulatory Elements in the Human Genome». Annual Review of Genomics and Human Genetics 7: 29-59. PMID 16719718. doi:10.1146/annurev.genom.7.080505.115623.
- ↑ Ogbourne, Steven; Antalis, Toni M. (1998). «Transcriptional control and the role of silencers in transcriptional regulation in eukaryotes». Biochemical Journal 331 (1): 1-14. ISSN 0264-6021. PMC 1219314. PMID 9512455. doi:10.1042/bj3310001.
- ↑ Buchler, N. E.; Gerland, U.; Hwa, T. (2003). «On schemes of combinatorial transcription logic». Proceedings of the National Academy of Sciences 100 (9): 5136-5141. Bibcode:2003PNAS..100.5136B. ISSN 0027-8424. PMC 404558. PMID 12702751. doi:10.1073/pnas.0930314100.
- ↑ Kazemian, M.; Pham, H.; Wolfe, S. A.; Brodsky, M. H.; Sinha, S. (11 de julio de 2013). «Widespread evidence of cooperative DNA binding by transcription factors in Drosophila development». Nucleic Acids Research 41 (17): 8237-8252. PMC 3783179. PMID 23847101. doi:10.1093/nar/gkt598.
- ↑ a b Guhaniyogi, Jayita; Brewer, Gary (2001). «Regulation of mRNA stability in mammalian cells». Gene 265 (1–2): 11-23. ISSN 0378-1119. PMC 3340483. PMID 11255003. doi:10.1016/S0378-1119(01)00350-X.
- ↑ Kuehner, Jason N.; Pearson, Erika L.; Moore, Claire (2011). «Unravelling the means to an end: RNA polymerase II transcription termination». Nature Reviews Molecular Cell Biology 12 (5): 283-294. ISSN 1471-0072. PMID 21487437. doi:10.1038/nrm3098.
- ↑ Mattick, J. S. (2006). «Non-coding RNA». Human Molecular Genetics 15 (90001): R17-R29. ISSN 0964-6906. PMID 16651366. doi:10.1093/hmg/ddl046.
- ↑ Palazzo, Alexander F.; Lee, Eliza S. (2015). «Non-coding RNA: what is functional and what is junk?». Frontiers in Genetics 6: 2. ISSN 1664-8021. PMC 4306305. PMID 25674102. doi:10.3389/fgene.2015.00002.
- ↑ Shafee, Thomas; Lowe, Rohan (2017). «Eukaryotic and prokaryotic gene structure». WikiJournal of Medicine 4 (1). ISSN 2002-4436. doi:10.15347/wjm/2017.002.
- ↑ Matera, A. Gregory; Wang, Zefeng (2014). «A day in the life of the spliceosome». Nature Reviews Molecular Cell Biology 15 (2): 108-121. ISSN 1471-0072. PMC 4060434. PMID 24452469. doi:10.1038/nrm3742.
- ↑ Salgado, H.; Moreno-Hagelsieb, G.; Smith, T.; Collado-Vides, J. (2000). «Operons in Escherichia coli: Genomic analyses and predictions». Proceedings of the National Academy of Sciences 97 (12): 6652-6657. Bibcode:2000PNAS...97.6652S. PMC 18690. PMID 10823905. doi:10.1073/pnas.110147297.
- ↑ Jacob, F.; Monod, J. (1 de junio de 1961). «Genetic regulatory mechanisms in the synthesis of proteins». Journal of Molecular Biology 3 (3): 318-356. ISSN 0022-2836. PMID 13718526. doi:10.1016/s0022-2836(61)80072-7.
- ↑ Tian, Tian; Salis, Howard M. (2015). «A predictive biophysical model of translational coupling to coordinate and control protein expression in bacterial operons». Nucleic Acids Research 43 (14): 7137-7151. ISSN 0305-1048. PMC 4538824. PMID 26117546. doi:10.1093/nar/gkv635.
- ↑ Schümperli, Daniel; McKenney, Keith; Sobieski, Donna A.; Rosenberg, Martin (1982). «Translational coupling at an intercistronic boundary of the Escherichia coli galactose operon». Cell 30 (3): 865-871. ISSN 0092-8674. PMID 6754091. doi:10.1016/0092-8674(82)90291-4.
- ↑ Levin-Karp, Ayelet; Barenholz, Uri; Bareia, Tasneem; Dayagi, Michal; Zelcbuch, Lior; Antonovsky, Niv; Noor, Elad; Milo, Ron (2013). «Quantifying Translational Coupling in E. coli Synthetic Operons Using RBS Modulation and Fluorescent Reporters». ACS Synthetic Biology 2 (6): 327-336. ISSN 2161-5063. PMID 23654261. doi:10.1021/sb400002n.
- ↑ Lewis, Mitchell (June 2005). «The lac repressor». Comptes Rendus Biologies 328 (6): 521-548. PMID 15950160. doi:10.1016/j.crvi.2005.04.004.
- ↑ McClure, W R (1985). «Mechanism and Control of Transcription Initiation in Prokaryotes». Annual Review of Biochemistry 54 (1): 171-204. ISSN 0066-4154. PMID 3896120. doi:10.1146/annurev.bi.54.070185.001131.
- ↑ Bell, Charles E; Lewis, Mitchell (2001). «The Lac repressor: a second generation of structural and functional studies». Current Opinion in Structural Biology 11 (1): 19-25. ISSN 0959-440X. PMID 11179887. doi:10.1016/S0959-440X(00)00180-9.
- ↑ Rodríguez-Trelles, Francisco; Tarrío, Rosa; Ayala, Francisco J. (2006). «Origins and Evolution of Spliceosomal Introns». Annual Review of Genetics 40 (1): 47-76. ISSN 0066-4197. PMID 17094737. doi:10.1146/annurev.genet.40.110405.090625.
Enlaces externos
- Esta obra contiene una traducción derivada de «Gene structure» de Wikipedia en inglés, concretamente de esta versión, publicada por sus editores bajo la Licencia de documentación libre de GNU y la Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
- GSDS - Servidor de visualización de estructura genética
 Datos: Q30587678
Datos: Q30587678