

A poison is any chemical substance that is harmful or lethal to living organisms. The term is used in a wide range of scientific fields and industries, where it is often specifically defined. It may also be applied colloquially or figuratively, with a broad sense.
Whether something is considered a poison or not may depend on the amount, the circumstances, and what living things are present. Poisoning could be accidental or deliberate, and if the cause can be identified there may be ways to neutralise the effects or minimise the symptoms.
In biology, a poison is a chemical substance causing death, injury or harm to organisms or their parts. In medicine, poisons are a kind of toxin that are delivered passively, not actively. In industry the term may be negative, something to be removed to make a thing safe, or positive, an agent to limit unwanted pests. In ecological terms, poisons introduced into the environment can later cause unwanted effects elsewhere, or in other parts of the food chain.
YouTube Encyclopedic
-
1/5Views:1 638 5672 185 8436 151 396139 7322 529 252
-
Pure arsenic is a scary poisonous rock
-
One Drop of This Poison Could Kill the Whole World
-
How deadly is cyanide?
-
The Chemistry of Poison Ivy
-
Your Body Will Never Survive 0.000,000,002 g Of This Poison
Transcription
Modern definitions
In broad metaphorical (colloquial) usage of the term, "poison" may refer to anything deemed harmful.
In biology, poisons are substances that can cause death, injury, or harm to organs, tissues, cells, and DNA usually by chemical reactions or other activity on the molecular scale, when an organism is exposed to a sufficient quantity.[1]
Medicinal fields (particularly veterinary medicine) and zoology often distinguish poisons from toxins and venoms. Both poisons and venoms are toxins, which are toxicants produced by organisms in nature.[2][3] The difference between venom and poison is the delivery method of the toxin.[2] Venoms are toxins that are actively delivered by being injected via a bite or sting through a venom apparatus, such as fangs or a stinger, in a process called envenomation,[4] whereas poisons are toxins that are passively delivered by being swallowed, inhaled, or absorbed through the skin.[2]
Uses
Industry, agriculture, and other sectors employ many poisonous substances, usually for reasons other than their toxicity to humans. (e.g. feeding chickens arsenic antihelminths[5][6]), solvents (e.g. rubbing alcohol, turpentine), cleaners (e.g. bleach, ammonia), coatings (e.g. Arsenic wallpaper), and so on. For example, many poisons are important feedstocks. The toxicity itself sometimes has economic value, when it serves agricultural purposes of weed control and pest control. Most poisonous industrial compounds have associated material safety data sheets and are classified as hazardous substances. Hazardous substances are subject to extensive regulation on production, procurement, and use in overlapping domains of occupational safety and health, public health, drinking water quality standards, air pollution, and environmental protection. Due to the mechanics of molecular diffusion, many poisonous compounds rapidly diffuse into biological tissues, air, water, or soil on a molecular scale. By the principle of entropy, chemical contamination is typically costly or infeasible to reverse, unless specific chelating agents or micro-filtration processes are available. Chelating agents are often broader in scope than the acute target, and therefore their ingestion necessitates careful medical or veterinarian supervision.
Pesticides are one group of substances whose prime purpose is their toxicity to various insects and other animals deemed to be pests (e.g., rats and cockroaches). Natural pesticides have been used for this purpose for thousands of years (e.g. concentrated table salt is toxic to many slugs and snails). Bioaccumulation of chemically-prepared agricultural insecticides is a matter of concern for the many species, especially birds, which consume insects as a primary food source. Selective toxicity, controlled application, and controlled biodegradation are major challenges in herbicide and pesticide development and in chemical engineering generally, as all lifeforms on earth share an underlying biochemistry; organisms exceptional in their environmental resilience are classified as extremophiles, these for the most part exhibiting radically different susceptibilities.
Ecological lifetime
A poison which enters the food chain—whether of industrial, agricultural, or natural origin—might not be immediately toxic to the first organism that ingests the toxin, but can become further concentrated in predatory organisms further up the food chain, particularly carnivores and omnivores, especially concerning fat soluble poisons which tend to become stored in biological tissue rather than excreted in urine or other water-based effluents.
Apart from food, many poisons readily enter the body through the skin and lungs. Hydrofluoric acid is a notorious contact poison, in addition to its corrosive damage. Naturally occurring sour gas is a fast-acting atmospheric poison, which can be released by volcanic activity or drilling rigs. Plant-based contact irritants, such as that possessed by poison ivy, are often classed as allergens rather than poisons; the effect of an allergen being not a poison as such, but to turn the body's natural defenses against itself. Poison can also enter the body through faulty medical implants, or by injection (which is the basis of lethal injection in the context of capital punishment).
In 2013, 3.3 million cases of unintentional human poisonings occurred.[7] This resulted in 98,000 deaths worldwide, down from 120,000 deaths in 1990.[8] In modern society, cases of suspicious death elicit the attention of the Coroner's office and forensic investigators.
Of increasing concern since the isolation of natural radium by Marie and Pierre Curie in 1898—and the subsequent advent of nuclear physics and nuclear technologies—are radiological poisons. These are associated with ionizing radiation, a mode of toxicity quite distinct from chemically active poisons. In mammals, chemical poisons are often passed from mother to offspring through the placenta during gestation, or through breast milk during nursing. In contrast, radiological damage can be passed from mother or father to offspring through genetic mutation, which—if not fatal in miscarriage or childhood, or a direct cause of infertility—can then be passed along again to a subsequent generation. Atmospheric radon is a natural radiological poison of increasing impact since humans moved from hunter-gatherer lifestyles and cave dwelling to increasingly enclosed structures able to contain radon in dangerous concentrations. The 2006 poisoning of Alexander Litvinenko was a notable use of radiological assassination, presumably meant to evade the normal investigation of chemical poisons.
Poisons widely dispersed into the environment are known as pollution. These are often of human origin, but pollution can also include unwanted biological processes such as toxic red tide, or acute changes to the natural chemical environment attributed to invasive species, which are toxic or detrimental to the prior ecology (especially if the prior ecology was associated with human economic value or an established industry such as shellfish harvesting).
The scientific disciplines of ecology and environmental resource management study the environmental life cycle of toxic compounds and their complex, diffuse, and highly interrelated effects.
Etymology
The word "poison" was first used in 1200 to mean "a deadly potion or substance"; the English term comes from the "...Old French poison, puison (12c., Modern French poison) "a drink", especially a medical drink, later "a (magic) potion, poisonous drink" (14c.), from Latin potionem (nominative potio) "a drinking, a drink", also "poisonous drink" (Cicero), from potare "to drink".[9] The use of "poison" as an adjective ("poisonous") dates from the 1520s. Using the word "poison" with plant names dates from the 18th century. The term "poison ivy", for example, was first used in 1784 and the term "poison oak" was first used in 1743. The term "poison gas" was first used in 1915.[9]
Terminology
The term "poison" is often used colloquially to describe any harmful substance—particularly corrosive substances, carcinogens, mutagens, teratogens and harmful pollutants, and to exaggerate the dangers of chemicals. Paracelsus (1493–1541), the father of toxicology, once wrote: "Everything is poison, there is poison in everything. Only the dose makes a thing not a poison"[10] (see median lethal dose). The term "poison" is also used in a figurative sense: "His brother's presence poisoned the atmosphere at the party". The law defines "poison" more strictly. Substances not legally required to carry the label "poison" can also cause a medical condition of poisoning.
Some poisons are also toxins, which is any poison produced by an organism, such as the bacterial proteins that cause tetanus and botulism. A distinction between the two terms is not always observed, even among scientists. The derivative forms "toxic" and "poisonous" are synonymous. Animal poisons delivered subcutaneously (e.g., by sting or bite) are also called venom. In normal usage, a poisonous organism is one that is harmful to consume, but a venomous organism uses venom to kill its prey or defend itself while still alive. A single organism can be both poisonous and venomous, but it is rare.[11]
All living things produce substances to protect them from getting eaten, so the term "poison" is usually only used for substances which are poisonous to humans, while substances that mainly are poisonous to a common pathogen to the organism and humans are considered antibiotics. Bacteria are for example a common adversary for Penicillium chrysogenum mold and humans, and since the mold's poison only targets bacteria, humans use it for getting rid of it in their bodies. Human antimicrobial peptides which are toxic to viruses, fungi, bacteria, and cancerous cells are considered a part of the immune system.[12]
In nuclear physics, a poison is a substance that obstructs or inhibits a nuclear reaction.
Environmentally hazardous substances are not necessarily poisons, and vice versa. For example, food-industry wastewater—which may contain potato juice or milk—can be hazardous to the ecosystems of streams and rivers by consuming oxygen and causing eutrophication, but is nonhazardous to humans and not classified as a poison.
Biologically speaking, any substance, if given in large enough amounts, is poisonous and can cause death. For instance, several kilograms worth of water would constitute a lethal dose. Many substances used as medications—such as fentanyl—have an LD50 only one order of magnitude greater than the ED50. An alternative classification distinguishes between lethal substances that provide a therapeutic value and those that do not.
Poisoning

Poisoning can be either acute or chronic, and caused by a variety of natural or synthetic substances. Substances that destroy tissue but do not absorb, such as lye, are classified as corrosives rather than poisons.
Acute
Acute poisoning is exposure to a poison on one occasion or during a short period of time. Symptoms develop in close relation to the exposure. Absorption of a poison is necessary for systemic poisoning. Furthermore, many common household medications are not labeled with skull and crossbones, although they can cause severe illness or even death. Poisoning can be caused by excessive consumption of generally safe substances, as in the case of water intoxication.
Agents that act on the nervous system can paralyze in seconds or less, and include both biologically derived neurotoxins and so-called nerve gases, which may be synthesized for warfare or industry.
Inhaled or ingested cyanide, used as a method of execution in gas chambers, or as a suicide method, almost instantly starves the body of energy by inhibiting the enzymes in mitochondria that make ATP. Intravenous injection of an unnaturally high concentration of potassium chloride, such as in the execution of prisoners in parts of the United States, quickly stops the heart by eliminating the cell potential necessary for muscle contraction.
Most biocides, including pesticides, are created to act as acute poisons to target organisms, although acute or less observable chronic poisoning can also occur in non-target organisms (secondary poisoning), including the humans who apply the biocides and other beneficial organisms. For example, the herbicide 2,4-D imitates the action of a plant hormone, which makes its lethal toxicity specific to plants. Indeed, 2,4-D is not a poison, but classified as "harmful" (EU).
Many substances regarded as poisons are toxic only indirectly, by toxication. An example is "wood alcohol" or methanol, which is not poisonous itself, but is chemically converted to toxic formaldehyde and formic acid in the liver. Many drug molecules are made toxic in the liver, and the genetic variability of certain liver enzymes makes the toxicity of many compounds differ between individuals.
Exposure to radioactive substances can produce radiation poisoning, an unrelated phenomenon.
Two common cases of acute natural poisoning are theobromine poisoning of dogs and cats, and mushroom poisoning in humans. Dogs and cats are not natural herbivores, but a chemical defense developed by Theobroma cacao can be incidentally fatal nevertheless. Many omnivores, including humans, readily consume edible fungi, and thus many fungi have evolved to become decisively inedible, in this case as a direct defense.
Chronic

Chronic poisoning is long-term repeated or continuous exposure to a poison where symptoms do not occur immediately or after each exposure. The person gradually becomes ill, or becomes ill after a long latent period. Chronic poisoning most commonly occurs following exposure to poisons that bioaccumulate, or are biomagnified, such as mercury, gadolinium, and lead.
Management
- Initial management for all poisonings includes ensuring adequate cardiopulmonary function and providing treatment for any symptoms such as seizures, shock, and pain.
- Injected poisons (e.g., from the sting of animals) can be treated by binding the affected body part with a pressure bandage and placing the affected body part in hot water (with a temperature of 50 °C). The pressure bandage prevents the poison being pumped throughout the body, and the hot water breaks it down. This treatment, however, only works with poisons composed of protein-molecules.[13]
- In the majority of poisonings the mainstay of management is providing supportive care for the patient, i.e., treating the symptoms rather than the poison.
Decontamination
- Treatment of a recently ingested poison may involve gastric decontamination to decrease absorption. Gastric decontamination can involve activated charcoal, gastric lavage, whole bowel irrigation, or nasogastric aspiration. Routine use of emetics (syrup of Ipecac), cathartics or laxatives are no longer recommended.
- Activated charcoal is the treatment of choice to prevent poison absorption. It is usually administered when the patient is in the emergency room or by a trained emergency healthcare provider such as a Paramedic or EMT. However, charcoal is ineffective against metals such as sodium, potassium, and lithium, and alcohols and glycols; it is also not recommended for ingestion of corrosive chemicals such as acids and alkalis.[14]
- Cathartics were postulated to decrease absorption by increasing the expulsion of the poison from the gastrointestinal tract. There are two types of cathartics used in poisoned patients; saline cathartics (sodium sulfate, magnesium citrate, magnesium sulfate) and saccharide cathartics (sorbitol). They do not appear to improve patient outcome and are no longer recommended.[15]
- Emesis (i.e. induced by ipecac) is no longer recommended in poisoning situations, because vomiting is ineffective at removing poisons.[16]
- Gastric lavage, commonly known as a stomach pump, is the insertion of a tube into the stomach, followed by administration of water or saline down the tube. The liquid is then removed along with the contents of the stomach. Lavage has been used for many years as a common treatment for poisoned patients. However, a recent review of the procedure in poisonings suggests no benefit.[17] It is still sometimes used if it can be performed within 1 hour of ingestion and the exposure is potentially life-threatening.
- Nasogastric aspiration involves the placement of a tube via the nose down into the stomach, the stomach contents are then removed by suction. This procedure is mainly used for liquid ingestions where activated charcoal is ineffective, e.g. ethylene glycol poisoning.
- Whole bowel irrigation cleanses the bowel. This is achieved by giving the patient large amounts of a polyethylene glycol solution. The osmotically balanced polyethylene glycol solution is not absorbed into the body, having the effect of flushing out the entire gastrointestinal tract. Its major uses are to treat ingestion of sustained release drugs, toxins not absorbed by activated charcoal (e.g., lithium, iron), and for removal of ingested drug packets (body packing/smuggling).[18]
Enhanced excretion
- In some situations elimination of the poison can be enhanced using diuresis, hemodialysis, hemoperfusion, hyperbaric medicine, peritoneal dialysis, exchange transfusion or chelation. However, this may actually worsen the poisoning in some cases, so it should always be verified based on what substances are involved.
Epidemiology
In 2010, poisoning resulted in about 180,000 deaths down from 200,000 in 1990.[19] There were approximately 727,500 emergency department visits in the United States involving poisonings—3.3% of all injury-related encounters.[20]
Applications
Poisonous compounds may be useful either for their toxicity, or, more often, because of another chemical property, such as specific chemical reactivity. Poisons are widely used in industry and agriculture, as chemical reagents, solvents or complexing reagents, e.g. carbon monoxide, methanol and sodium cyanide, respectively. They are less common in household use, with occasional exceptions such as ammonia and methanol. For instance, phosgene is a highly reactive nucleophile acceptor, which makes it an excellent reagent for polymerizing diols and diamines to produce polycarbonate and polyurethane plastics. For this use, millions of tons are produced annually. However, the same reactivity makes it also highly reactive towards proteins in human tissue and thus highly toxic. In fact, phosgene has been used as a chemical weapon. It can be contrasted with mustard gas, which has only been produced for chemical weapons uses, as it has no particular industrial use.
Biocides need not be poisonous to humans, because they can target metabolic pathways absent in humans, leaving only incidental toxicity. For instance, the herbicide 2,4-dichlorophenoxyacetic acid is a mimic of a plant growth hormone, which causes uncontrollable growth leading to the death of the plant. Humans and animals, lacking this hormone and its receptor, are unaffected by this, and need to ingest relatively large doses before any toxicity appears. Human toxicity is, however, hard to avoid with pesticides targeting mammals, such as rodenticides.
The risk from toxicity is also distinct from toxicity itself. For instance, the preservative thiomersal used in vaccines is toxic, but the quantity administered in a single shot is negligible.
-
 Deaths from poisonings per million persons in 20120-23-56-78-1011-1213-1920-2728-4142-5556-336
Deaths from poisonings per million persons in 20120-23-56-78-1011-1213-1920-2728-4142-5556-336 -
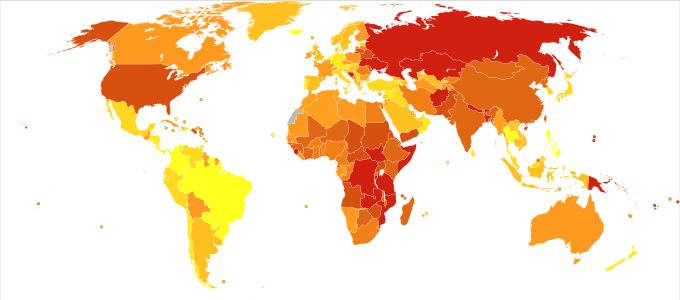
![Disability-adjusted life year for poisonings per 100,000 inhabitants in 2004.[21]](//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Poisonings_world_map_-_DALY_-_WHO2004.svg/680px-Poisonings_world_map_-_DALY_-_WHO2004.svg.png) Disability-adjusted life year for poisonings per 100,000 inhabitants in 2004.[21]
Disability-adjusted life year for poisonings per 100,000 inhabitants in 2004.[21]

![Disability-adjusted life year for poisonings per 100,000 inhabitants in 2004.[21]](http://upload.wikimedia.org/wikipedia/commons/thumb/3/36/Poisonings_world_map_-_DALY_-_WHO2004.svg/680px-Poisonings_world_map_-_DALY_-_WHO2004.svg.png)
History

Throughout human history, intentional application of poison has been used as a method of murder, pest-control, suicide, and execution.[22][23] As a method of execution, poison has been ingested, as the ancient Athenians did (see Socrates), inhaled, as with carbon monoxide or hydrogen cyanide (see gas chamber), injected (see lethal injection), or even as an enema.[24] Poison's lethal effect can be combined with its allegedly magical powers; an example is the Chinese gu poison. Poison was also employed in gunpowder warfare. For example, the 14th-century Chinese text of the Huolongjing written by Jiao Yu outlined the use of a poisonous gunpowder mixture to fill cast iron grenade bombs.[25]
While arsenic is a naturally occurring environmental poison, its artificial concentrate was once nicknamed inheritance powder.[26] In Medieval Europe, it was common for monarchs to employ personal food tasters to thwart royal assassination, in the dawning age of the Apothecary.
Figurative use
The term poison is also used in a figurative sense. The slang sense of alcoholic drink is first attested 1805, American English (e.g., a bartender might ask a customer "what's your poison?" or "Pick your poison").[9] Figurative use of the term dates from the late 15th century.[27] Figuratively referring to persons as poison dates from 1910.[27] The figurative term poison-pen letter became well known in 1913 by a notorious criminal case in Pennsylvania, U.S.; the phrase dates to 1898.
See also
- Agency for Toxic Substances and Disease Registry (ATSDR) – US federal agency
- Antidote – Substance that can counteract a form of poisoning
- Biosecurity – Preventive measures designed to reduce the risk of infectious disease transmission
- Contaminated haemophilia blood products – Health crisis in the late 1970s up to 1985
- Food taster – Person ingesting food prepared for someone else to ensure it's safe to eat
- Infection – Invasion of an organism's body by pathogenic agents
- EPA list of extremely hazardous substances
- Lists of poisonings
- List of poisonous plants
- List of types of poison
- Mr. Yuk – Label that indicates poisonous material
- Poison ring – Ring with concealed compartment which could be used to store poison
- Saxitoxin – Paralytic shellfish toxin
- Toxics use reduction – Approach to pollution prevention
- Toxic waste – Any unwanted material which can cause harm
References
- ^ "Poison" at Merriam-Webster. Retrieved December 26th, 2014.
- ^ a b c "Poison vs. Venom". Australian Academy of Science. 3 November 2017. Retrieved 17 April 2022.
- ^ Chippaux, JP; Goyffon, M (2006). "[Venomous and poisonous animals--I. Overview]". Médecine Tropicale (in French). 66 (3): 215–20. ISSN 0025-682X. PMID 16924809.
- ^ Gupta, Ramesh C., ed. (24 March 2017). Reproductive and developmental toxicology. Saint Louis: Elsevier Science. pp. 963–972. ISBN 978-0-12-804240-3. OCLC 980850276.
- ^ Hunt, Chris (13 May 2013). "The Arsenic in Your Chicken". Huffington Post.
- ^ "Did the FDA Admit That 70% of U.S. Chickens Contain Arsenic?". Snopes. 20 Jan 2015.
- ^ Global Burden of Disease Study 2013 collaborators (22 August 2015). "Global, regional, and national incidence, prevalence, and years lived with disability for 301 acute and chronic diseases and injuries in 188 countries, 1990-2013: a systematic analysis for the Global Burden of Disease Study 2013". Lancet. 386 (9995): 743–800. doi:10.1016/s0140-6736(15)60692-4. PMC 4561509. PMID 26063472.
- ^ GBD 2013 Mortality and Causes of Death collaborators (17 December 2014). "Global, regional, and national age-sex specific all-cause and cause-specific mortality for 240 causes of death, 1990-2013: a systematic analysis for the Global Burden of Disease Study 2013". Lancet. 385 (9963): 117–71. doi:10.1016/S0140-6736(14)61682-2. PMC 4340604. PMID 25530442.
- ^ a b c "poison - Search Online Etymology Dictionary". www.etymonline.com. Retrieved 3 November 2017.
- ^ Latin: Dosis sola venenum facit. Paracelsus: Von der Besucht, Dillingen, 1567
- ^ Hutchinson DA, Mori A, Savitzky AH, Burghardt GM, Wu X, Meinwald J, Schroeder FC (2007). "Dietary sequestration of defensive steroids in nuchal glands of the Asian snake Rhabdophis tigrinus". Proceedings of the National Academy of Sciences of the United States of America. 104 (7): 2265–70. Bibcode:2007PNAS..104.2265H. doi:10.1073/pnas.0610785104. PMC 1892995. PMID 17284596.
- ^ Reddy KV, Yedery RD, Aranha C (2004). "Antimicrobial peptides: premises and promises". International Journal of Antimicrobial Agents. 24 (6): 536–547. doi:10.1016/j.ijantimicag.2004.09.005. PMID 15555874.
- ^ Complete diving manual by Jack Jackson
- ^ Chyka PA, Seger D, Krenzelok EP, Vale JA (2005). "Position paper: Single-dose activated charcoal". Clin Toxicol. 43 (2): 61–87. doi:10.1081/CLT-51867. PMID 15822758. S2CID 218856921.
- ^ Toxicology, American Academy of Clinical (2004). "Position paper: cathartics". J Toxicol Clin Toxicol. 42 (3): 243–253. doi:10.1081/CLT-120039801. PMID 15362590. S2CID 46629852.
- ^ American Academy of Clinical Toxicology; European Association of Poisons Centres Clinical Toxicologists (2004). "Position paper: Ipecac syrup". J Toxicol Clin Toxicol. 42 (2): 133–143. doi:10.1081/CLT-120037421. PMID 15214617. S2CID 218865551.
- ^ Vale JA, Kulig K (2004). "Position paper: gastric lavage". J Toxicol Clin Toxicol. 42 (7): 933–43. doi:10.1081/clt-200045006. PMID 15641639. S2CID 29957973.
- ^ "Position paper: whole bowel irrigation". J Toxicol Clin Toxicol. 42 (6): 843–854. 2004. doi:10.1081/CLT-200035932. PMID 15533024. S2CID 800595.
- ^ Lozano, R (Dec 15, 2012). "Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010". Lancet. 380 (9859): 2095–128. doi:10.1016/S0140-6736(12)61728-0. hdl:10536/DRO/DU:30050819. PMC 10790329. PMID 23245604. S2CID 1541253.
- ^ Villaveces A, Mutter R, Owens PL, Barrett ML. Causes of Injuries Treated in the Emergency Department, 2010. HCUP Statistical Brief #156. Agency for Healthcare Research and Quality. May 2013.[1] Archived 2017-01-20 at the Wayback Machine
- ^ "WHO Disease and injury country estimates". World Health Organization. 2004. Retrieved Nov 11, 2009.
- ^ Kautilya suggests employing means such as seduction, secret use of weapons, poison etc. S.D. Chamola, Kautilya Arthshastra and the Science of Management: Relevance for the Contemporary Society, p. 40. ISBN 81-7871-126-5.
- ^ Kautilya urged detailed precautions against assassination—tasters for food, elaborate ways to detect poison. Boesche Roger (2002). "Moderate Machiavelli? Contrasting The Prince with the Arthashastra of Kautilya". Critical Horizons: A Journal of Philosophy. 3 (2): 253–276. doi:10.1163/156851602760586671. S2CID 153703219..
- ^ Julius Friedenwald and Samuel Morrison (January 1940). "The History of the Enema with Some Notes on Related Procedures (Part I)". Bulletin of the History of Medicine. 8 (1): 113. JSTOR 44442727.
- ^ Needham, Joseph (1986). Science and Civilization in China: Volume 5, Part 7. Taipei: Caves Books, Ltd. Page 180.
- ^ Yap, Amber (14 November 2013). "Arsenic The "Inheritance Powder."". prezi.com. Prezi. Retrieved 19 March 2018.
- ^ a b "Online Etymology Dictionary". www.etymonline.com. Archived from the original on 5 December 2015. Retrieved 3 November 2017.
External links
- National Capital Poison Center
- webPOISONCONTROL(R)
- Agency for Toxic Substances and Disease Registry
- American Association of Poison Control Centers
- American College of Medical Toxicology
- Clinical Toxicology Teaching Wiki Archived 2009-04-22 at the Wayback Machine
- Find Your Local Poison Control Centre Here (Worldwide)
- Poison Prevention and Education Website
- Cochrane Injuries Group Archived 2020-08-03 at the Wayback Machine, Systematic reviews on the prevention, treatment and rehabilitation of traumatic injury (including poisoning)
- Pick Your Poison—12 Toxic Tales by Cathy Newman
| Inorganic |
| ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Organic |
| ||||||||||||
| Pharmaceutical |
| ||||||||||||
| Biological2 |
| ||||||||||||
| Miscellaneous | |||||||||||||
| |||||||||||||
| Fields | |
|---|---|
| Concepts | |
| Treatments | |
| Incidents | |
| Related topics | |
| National | |
|---|---|
| Other | |