
| Kannauji | |
|---|---|
| कन्नौजी | |
| Native to | India |
| Region | Kannauj |
Native speakers | 9.5 million (2001)[1] |
| Devanagari | |
| Language codes | |
| ISO 639-3 | bjj |
| Glottolog | kana1281 |
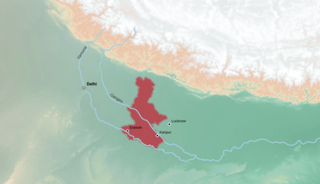 Area depicting Kannauji speaking region in Uttar Pradesh, India. | |
Kannauji is an Indo-Aryan language spoken in the Kannauj region of the Indian state of Uttar Pradesh. Kannauji is closely related to Hindustani, with a lexical similarity of 83–94% with Hindi.[2] Some consider it to be a dialect of Hindustani, whereas others consider it a separate Western Hindi language.[3] Kannauji has at least 9.5 million native speakers as of 2001.
Kannauji shares many structural and functional differences from other dialects of Hindi, but in the Linguistic Survey of India it has been added as a variant of Braj and Awadhi.
Kannauji has two dialects or variants of its own: Tirhari and Transitional Kannauji, which is between standard Kannauji and Awadhi.
Geographical distribution
Kannauji is not a standard dialect of Hindi and can be assumed to be the transitory phase between Braj Bhasha and Awadhi. Eastern parts are heavily influenced by Awadhi whereas Western districts are Braj speaking. Kannauji is predominantly spoken around the historic town of Kannauj in the following districts of the Ganga-Yamuna Doab:
In the non-Doabi areas, it is spoken in Hardoi, western parts of Lakhimpur Kheri and Sitapur districts in Awadh and Shahjahanpur and Pilibhit of Rohilkhand.
A distribution of the geographical area can be found in volume 9 of 'Linguistic Survey of India' by George A. Grierson.
The population of the region is 22,011,017.[4]
Works
Phonology
Consonants
| Labial | Dental/ Alveolar |
Retroflex | Palatal | Velar | Uvular | Glottal | ||
|---|---|---|---|---|---|---|---|---|
| Nasal | m | n | (ɳ) | (ɲ) | (ŋ) | |||
| Plosive/ Affricate |
voiceless | p | t̪ | ʈ | tʃ | k | ||
| voiceless aspirated | pʰ | t̪ʰ | ʈʰ | tʃʰ | kʰ | |||
| voiced | b | d̪ | ɖ | dʒ | ɡ | |||
| voiced aspirated | bʱ | d̪ʱ | ɖʱ | dʒʱ | ɡʱ | |||
| Fricative | voiceless | (f) | s | (ʃ) | ||||
| voiced | (v) | (z) | ɦ | |||||
| Flap | plain | ɾ | (ɽ) | |||||
| voiced aspirated | (ɽʱ) | |||||||
| Approximant | ʋ | l | j | |||||
Grammar
There is no published grammar of Kannauji till date, but some of the basic features of Kannauji, which can be observed easily, are as below:
Kannauji is a Prodrop language. In such languages pronouns are dropped for the convenience of the speaker. (This feature includes pronouns of WH category, too.) For example,
- ka: tum huan jaiyo:
can also be said huan jaiyo:
Word formation processes
Word formation processes of Kannauji are more or less like of Hindi, but some processes of word formation of Kannauji are not found in Hindi. Here are the word formation processes of Kannaiji:
Borrowing words
In borrowing something from other language is taken directly into a language. It is a very common and very productive process of word formation.
On the lexical and semantic basis we can divide borrowing in two types:
Lexical borrowing (loan words)
In lexical borrowing a word is directly taken into a language from other language. Lexical borrowing is very common in Kannauji.
Sometimes a word is not borrowed as it is. Some phonetic changes are made to it to match the properties of target language. The word is localised for ease of native speakers. For example:
| Source word | Language | Adapted in Kannauji as |
|---|---|---|
| Computer | English | [kampu:tar] |
| Solution | English | [salu:san] |
| Problem | English | [pira:balam] |
Semantic borrowing (calque)
In semantic borrowing some concept from another language is taken into a language, but the words used to express that concept are made in the target language. In this type of borrowing concepts/words are localised. For example:
| Concept | Word | Adapted in Kannauji as |
|---|---|---|
| Computation | Computation | [sanganan] |
Coining
Coining is a less frequent and a less productive word formation process. In coining meaning of a word is extended up to an extent that it starts being used as a category. Here are some examples of coining.
- chyawanpra:sh was a product made by Dabur. After that, many other companies launched their similar products. The name of chyawanpra:sh became so popular that now every such product is known as chyawanpra:sh.
- pachmo:la: When Vaidyanaath launched its digestive tablets it named them pachmo:la:. This product became so popular that afterwards all such products are known as pachmo:la:.
Word formation by addition
In Kannauji new words are formed by inflection old words, too. According to different properties this process is divided into two main types:
Inflection
In inflection a new word is formed from an old word by adding something in it. It is the most common process of word formation in Kannauji. This process is category specific. The grammatical category of a word remains same even after inflection.
For example:
-ini
ladka + '-ini' = ladkini
(boy) (girl)
Here '–ini' is used to make a feminine form of the word ladka. Here is another example of inflection:
sangi + '-ini' = sangini (mate- male) (mate- female)
Derivation-
In derivation, too, new words are formed by old words using affixes. This is a very common process like inflection. There are three types of affixation found in Kannauji.
Prefix
In this type of affixation an affix is inserted initially in a word.
- ‘ap-’
'ap-' + jash → apjash
(evil) (fame)
- ‘par-’
'par-' + dosh → pardo:sh
(others) (defects)
‘ap’ and ‘par’ are prefixes here. New words are being formed by adding them to two old words ‘jash’ and ‘dosh’.
Suffix
In this type of affixation an affix is inserted at the end of a word; this way a new word is formed.
- ‘-aevo’
dikha:na: + -aevo → dikhaevo
(showing)
rakhna: + -aevo → rakhaevo
(keeping)
- ‘-pan’
apna + -pan → apno:pan
(self)
Infix
In this type of affixation an affix inserted somewhere in the middle of the word.
- ‘-la-’
dikh aevo: + -la- → dikhlaevo:
(showing)(making something show by some other person)
- ‘-va-’
hasa evo: + -va- → hasavaevo:
(to make laugh)(causing people laugh by some other person)
Blending
Blending is the process in which parts of two words (which are already present in that language) are joined to make a new word.
choti: + bit͜ti: →chotit͜ti:
(small) (girl)
badi: + bit͜ti: →badit͜ti:
(big) (girl)
bade: + dad͜da: →badid͜da:
(big) (brother)
Compounding
In compounding two words are stringed together to form a new word. This process is a common word formation process. This type of formation process is used more by educated persons.
For example:
guru + ghantal = gurughantal
Here gurughantal is made by stringing guru and ghantal and the meaning referred by the stringed word is reflected by the words. Although it is not necessary in every condition. For example:
am͜ma aur dad͜da → am͜ma: dad͜da:
Conversion
Conversion is a very productive but less frequent process of word formation. In this process a word starts being used as another word (having some similar properties).
In this process a word of some grammatical category starts being using as word of other grammatical category, too. Here are some examples of conversion.
- wao: baura: hai (He is a moron)
- baurane: kahe: hau: dadda: (Why are you behaving like a moron?)
Baura is an abstract noun. In the first sentence baura: is used as an abstract noun. After conversion it started being used as a verb also, as in the second sentence.
Suppletion
In suppletion another relative form of a word is formed without any morpho-phonological similarities with the previous one. These forms do not relate morphologically or phonologically. For example:
ja:t and gao:
ja:t - ham ja:t hai
gao: - wao gao: hato
‘ja:t’ is present participle for very ‘go’ whereas ‘gao:’ is the past participle form.
Reduplication
Reduplication is a very common process of word formation in Kannauji. Most of the reduplicated forms are made by adjectival and nominal words. This is not a productive type of word formation process; instead it adds stylistic effect in conversation. For example:
ghare-ghare
Here ghare is formed following the word ghare so it is an example of reduplication.
Echo formation
Echo formation is a similar process to reduplication. In echo formation, a similar-sounding word is made from nominal and adjectival. There is no logic behind why this formation is done but it increases the stylistic effectiveness of conversation. For example:
tasla-wasla
Here wasla, a similar-sounding word is formed after word tasla so it is an example of eco formation process. Some other examples are
- haldi-waldi
- ata-wata
Metaphoric expansion-
In metaphor a word is objected on another one because of some similarity. In metaphoric expansion a word is used in different situations and environments due to one similar quality. The meaning of a word is expanded metaphorically in this word formation process. For example:
dama:d → sarka:r ko dama:d
dama:d is a son-in-law . So sarka:r ko dama:d is used to refer a person who is favoured very much by government. Here is another example of metaphoric expansion-
shekhchil͜li: → gao ke shekhchil͜li:
Onomatopoeic words
Onomatopoeic words are supposed as absolute or original words. They sound like the actions and things they are related to. For example:
- khatar-patar It is a sound made by friction of two heavy objects.
- dhum-dhama:ko: It sounds similar to firing something.
- satar-patar
References
- ^ Kannauji at Ethnologue (18th ed., 2015) (subscription required)
- ^ Ethnologue
- ^ Kannauji
- ^ "Kannauj Region Population". 4 November 2021.
- ^ http://censusindia.gov.in/. Retrieved 4 November 2021.
{{cite web}}: Missing or empty|title=(help) - ^ Dwivedi, Pankaj; Kar, Somdev (2016). "Kanauji of Kanpur: A Brief Overview". Acta Linguistica Asiatica. 6 (1): 101–119. doi:10.4312/ala.6.1.101-119.
Further reading
- http://www.sumania.com/lang/allindi4.html
- Dwivedi, Pankaj; Kar, Somdev (2016). "Kanauji of Kanpur: A Brief Overview". Acta Linguistica Asiatica. 6 (1): 101–119. doi:10.4312/ala.6.1.101-119.
- Dwivedi, P., & Kar, S. (2017). On documenting low resourced Indian languages insights from Kanauji speech corpus. Dialectologia: revista electrònica, (19), 67-91. https://www.raco.cat/index.php/Dialectologia/article/view/328489
- Dwivedi, P., & Kar, S. (September 2016). SOCIOLINGUISTICS AND PHONOLOGY OF KANAUJI. In International Conference on Hindi Studies. https://www.researchgate.net/profile/Pankaj_Dwivedi4/publication/308198142_Sociolinguistics_and_Phonology_of_Kanauji/links/57ea51bd08aed0a291332dc2.pdf
- Dwivedi, P. &Kar, S. (2018). Phonology of Kanauji. In Sharma, Ghanshyam (Eds.) Advances in Hindi Language Teaching and Applied Linguistics (1). 189-220. Germany: Lincom Europa.