
The African reference alphabet is any of several proposed guidelines for the creation of Latin alphabets for African languages. The initial proposals were made at a 1978 UNESCO-organized conference held in Niamey, Niger, based on the results of several earlier conferences on the harmonization of the Latin alphabets of individual languages, with a substantial overhaul proposed in 1982. None have official standing. The 1978 conference recommended the use of single letters for speech sounds (that is, phonemes) instead of two-letter or three-letter sequences, or of letters with diacritics.
The proposals inherit from the Africa Alphabet, and like the latter use a number of IPA letters. The Niamey conference built on the work of a previous UNESCO-organized meeting, on harmonizing the transcriptions of African languages, that was held in Bamako, Mali, in 1966.
YouTube Encyclopedic
-
1/5Views:225 4302 013 97923 165119 9307 114 607
-
Why was the first Afrikaans written in Arabic Letters?
-
Evolution of the Alphabet | Earliest Forms to Modern Latin Script
-
How to write the N'ko alphabet (ߒߞߏ) of West Africa: A tutorial!
-
Learn Akan (Twi) Grammar | The Akan Alphabet | Lesson 1 | LEARNAKAN.COM
-
ABCD matching|lkg class english worksheet|abc matching|match the later with picture|#Success4AllExam
Transcription
1978 proposals
Separate versions of the conference's report were produced in English and French. Different images of the alphabet were used in the two versions, and there are a number of differences between the two.
The English version was a set of 57 letters, given in both upper-case and lower-case forms. Eight of these are formed from common Latin letters with the addition of an underline mark. Some (the uppercase letters alpha, eth (![]() ), esh, and both lower- and upper-case
), esh, and both lower- and upper-case ![]() ,
, ![]() ) cannot be accurately represented in Unicode (as of version 15, 2023). Others do not correspond to the upper- and lower-case identities in Unicode, or (e.g. Ʒ) require character variants in the font.[1]
) cannot be accurately represented in Unicode (as of version 15, 2023). Others do not correspond to the upper- and lower-case identities in Unicode, or (e.g. Ʒ) require character variants in the font.[1]
This version also listed eight diacritical marks (acute accent (´), grave accent (`), circumflex (ˆ), caron (ˇ), macron (¯), tilde (˜), trema (¨), and a superscript dot (˙) and nine punctuation marks (? ! ( ) « » , ; .).
In the French version, the letters were hand-printed in lower case only. Only 56 of the letters in the English version were listed – omitting the hooktop-z – and two further apostrophe-like letters were included (for ʔ and ʕ); these are placed lower than punctuation marks would be. Five of the letters were written with a subscript dot instead of a subscript dash as in the English version (ḍ ḥ ṣ ṭ and ẓ). (These represent Arabic-style emphatic consonants; the remaining underlined letters (c̠, q̠ and x̠) represent clicks.) Diacritical marks and punctuation are not shown. The French and English sets are otherwise identical.


| lowercase | a | α | b | ɓ | c | c̠ | d | d̠ | ɖ | ɗ | ð | |
| uppercase | A | Ɑ | B | Ɓ | C | C̠ | D | D̠ | Ɖ | Ɗ | Ꝺ | |
| lowercase | e | ɛ | ǝ | f | ƒ | ɡ | ɣ | h | h̠ | i | ɪ | |
| uppercase | E | Ɛ | Ǝ | F | Ғ | G | Ɣ | H | H̠ | I | Ɪ | |
| lowercase | j | k | ƙ | l | m | n | ŋ | o | ɔ | p | q | |
| uppercase | J | K | Ƙ | L | M | N | Ŋ | O | Ɔ | P | Q | |
| lowercase | q̠ | r | ɍ | s | s̠ | ʃ | t | t̠ | ƭ | ʈ | ө | u |
| uppercase | Q̠ | R | Ɍ | S | S̠ | Ʃ | T | T̠ | Ŧ | ϴ | U | |
| lowercase | ᴜ | v | ʋ | w | x | x̠ | y | ƴ | z | z̠ | ʒ | |
| uppercase | Ʊ | V | Ʋ | W | X | X̠ | Y | Ƴ | Z | Z̠ |
| a | α | b | ɓ | c | c̱ | d | ḍ | ɖ | ɗ | ð | |
| e | ɛ | ǝ | f | ƒ | ɡ | ɣ | h | ḥ | i | ɪ | |
| j | k | ƙ | l | m | n | ŋ | o | ɔ | p | q | q̱ |
| r | ɍ | s | ṣ | ʃ | t | ṭ | ʈ | ƭ | ө | u | ᴜ |
| v | ʋ | w | x | x̱ | y | ƴ | z | ẓ | ʒ | ʼ | ʻ |
Notes:
- Ɑ/ɑ is "Latin alpha" (

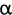 ) not "Latin script a" (
) not "Latin script a" (
 ). In Unicode, Latin alpha and script a are not considered as separate characters.
). In Unicode, Latin alpha and script a are not considered as separate characters. - The upper case I, the counterpart of the lower case i, does not have crossbars (
 ) while the upper case counterpart of the lower case ɪ has them (
) while the upper case counterpart of the lower case ɪ has them (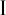 ).
). - The letter “Z with tophook” (
 ) is not included in Unicode.
) is not included in Unicode. - c̠, q̠, x̠ represent click consonants (ǀ, ǃ, ǁ respectively), but the line under is optional, and usually not used.[2]
- c, j represent either palatal stops or postalveolar affricates. ɖ, ʈ are the retroflex stops, as in the IPA.
- ƒ, ʋ represent bilabial fricatives.
- ө is a dental fricative, not a vowel.
- Although digraphs using h are normally used to represent aspirated consonants, in languages in which those are absent, the digraphs can be used instead of ʒ, ʃ, ө, ɣ...[2]
- Digraphs with m or n are used for prenasalized consonants, with w and y for labialized and palatalized consonants; kp and gb are used for labial-velar stops; hl and dl are used for lateral fricatives.[2]
- ɓ, ɗ are used for implosives, and ƭ, ƙ for either ejectives or voiceless implosives. ƴ is used for [ʔʲ].
- Nasalization is either written with a nasal consonant following the vowel, or with a tilde. Tone is indicated using the acute accent, grave accent, caron, macron, and circumflex. Diaeresis is used for centralized vowels, and vowel length is indicated by doubling the vowel.
- Segmentation should be done according to each language's own phonology and morphology.
Rejected 1982 proposal
A proposed revision of the alphabet was made in 1982 by Michael Mann and David Dalby, who had attended the Niamey conference. It has 60 letters. Digraphs are retained only for vowel length and geminate consonants, and even there they suggest replacements. A key feature of this proposal is that, like the French proposal of 1978, it consists of only lower-case letters, making it unicase. It did not meet with acceptance at the follow-up Niamey meeting in 1984.[3]

| a | α | ʌ | b | ɓ | c | ꞇ | ç | d | ɗ | ɖ | ꝺ | e | ɛ | ǝ |
| f | ƒ | g | ɠ | ɣ | h | ɦ | i | ɩ | j | ɟ | k | ƙ | l | λ |
| m | ɴ | n | ŋ | ɲ | o | ɔ | p | ƥ | q | r | ɽ | s | ʃ | t |
| ƭ | ʈ | θ | u | ω | v | ʋ | w | x | y | ƴ | z | ʒ | ƹ | ʔ |
The 32nd letter “![]() ” is called linearized tilde.[5] It is not specifically supported in Unicode (as of version 15, 2023), but can be represented by ⟨ɴ⟩ or ⟨∿⟩. ⟨ ƒ ⟩ and ⟨ ʃ ⟩ are written without ascenders (thus esh is a mirror of ⟨ʅ ⟩; ⟨ƴ⟩ is written with a right-hooking tail, like the retroflex letters in the IPA; and ⟨ɩ⟩ has a top hook to the left, like a squashed ⟨ʅ ⟩.
” is called linearized tilde.[5] It is not specifically supported in Unicode (as of version 15, 2023), but can be represented by ⟨ɴ⟩ or ⟨∿⟩. ⟨ ƒ ⟩ and ⟨ ʃ ⟩ are written without ascenders (thus esh is a mirror of ⟨ʅ ⟩; ⟨ƴ⟩ is written with a right-hooking tail, like the retroflex letters in the IPA; and ⟨ɩ⟩ has a top hook to the left, like a squashed ⟨ʅ ⟩.
Because no language has all the consonants, the consonant letters are used for more than one potential value. They can be reassigned when there are conflicts. For instance, ɦ may be either a voiceless pharyngeal or a voiced glottal fricative.
| bilabial | labio- dental |
labio- velar |
dental | alveolar | lateral | post- alveolar/ retroflex |
alveo- palatal |
palatal | velar | uvular | pharyn- geal |
glottal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| nasal | m | ɴ | n | ɴ | ɲ | ŋ | |||||||
| plosive | p b | ƥ ɓ | t d | ʈ ɖ | c j | k g | q | ʔ | |||||
| implosive | ɓ | ɗ | ƴ | ɠ | |||||||||
| ejective/ aspirate |
ƥ | ƭ | ꞇ | ƙ | |||||||||
| click | ω | ʈ | ɖ | λ | ç | ||||||||
| affricate | c j | ||||||||||||
| fricative | ƒ ʋ | f v | θ ꝺ | s z | θ ꝺ | ʃ ʒ | ç ɟ | x ɣ | ɦ ƹ | h ɦ | |||
| trill/flap | r | ɽ | ɽ | ||||||||||
| approximant | ʋ | w | l | λ | y | ||||||||
Where ⟨ƥ ɓ⟩ are needed for both values, ⟨ƙ ɠ⟩ might be chosen for the labiovelar plosives.
Where dentals contrast with alveolars, ⟨ƭ ɗ ɴ⟩ might be chosen for the dentals.
Where there are aspirated plosives but not voiced, the pinyin solution might be chosen of using voiced letters (e.g. b) for tenuis and the voiceless letter (e.g. p) for the aspirate.
Additional affricates should be written with unused letters, or with digraphs in y or w where there is morphophonemic justification.
Where ⟨θ ꝺ⟩ are needed for both values, the lateral fricatives might be written ⟨λ ɽ⟩.
Where velar and uvular fricatives contrast, ⟨ɦ ɽ⟩ might be chosen for the uvulars.
Where ⟨ʋ⟩ is needed for both values, ⟨ω⟩ might be chosen for the approximant.
The click letters are combined with ɴ (before or after) for nasal clicks, followed by g for voiced, and followed by h for aspirated.
| front | central | back | |
|---|---|---|---|
| close | i | ɩ | u |
| close-mid | e | ω | o |
| open-mid | ɛ | ə | ɔ |
| open | a | ʌ | α |
Remaining diacritics should be replaced by linearized equivalents. For the tone diacritics are proposed baseline-aligned ⟨´ ` ⌟ ⌝⟩ (not supported by Unicode).
See also
References
- ^ a b c d e "Presentation of the "African Reference Alphabet" (in 4 images) from the Niamey 1978 meeting". www.bisharat.net. Retrieved 2013-05-10.
- ^ a b c "Niamey 1978 report". www.bisharat.net. Retrieved 2021-08-18.
- ^ P. Baker (1997: 115) Developing ways of writing vernaculars, in Tabouret-Keller et al. (eds.) Vernacular Literacy. Clarendon and Oxford Press.
- ^ a b c d Michael Mann & David Dalby 1987 [2017] A Thesaurus of African Languages: A Classified and Annotated Inventory of the Spoken Languages of Africa With an Appendix on Their Written Representation. London, ISBN 0-905450-24-8, p. 207
- ^ Mann, Michael; Dalby, David: A Thesaurus of African Languages, London 1987, ISBN 0-905450-24-8, p. 210
Further reading
- Mann, Michael; Dalby, David (1987). A thesaurus of African languages: A classified and annotated inventory of the spoken languages of Africa with an appendix on their written representation. London: Hans Zell Publishers. ISBN 0-905450-24-8.
External links
- African Languages: Proceedings of the meeting of experts on the transcription and harmonization of African languages, Niamey (Niger), 17–21 July 1978, Paris: UNESCO, 1981
- http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IntlNiameyKybd
- http://www.bisharat.net/Documents/Niamey78annex.htm