
| Binary search tree | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type | tree | |||||||||||||||||||||||
| Invented | 1960 | |||||||||||||||||||||||
| Invented by | P.F. Windley, A.D. Booth, A.J.T. Colin, and T.N. Hibbard | |||||||||||||||||||||||
| ||||||||||||||||||||||||
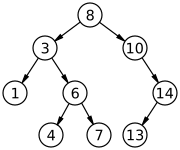
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.
Binary search trees allow binary search for fast lookup, addition, and removal of data items. Since the nodes in a BST are laid out so that each comparison skips about half of the remaining tree, the lookup performance is proportional to that of binary logarithm. BSTs were devised in the 1960s for the problem of efficient storage of labeled data and are attributed to Conway Berners-Lee and David Wheeler.
The performance of a binary search tree is dependent on the order of insertion of the nodes into the tree since arbitrary insertions may lead to degeneracy; several variations of the binary search tree can be built with guaranteed worst-case performance. The basic operations include: search, traversal, insert and delete. BSTs with guaranteed worst-case complexities perform better than an unsorted array, which would require linear search time.
The complexity analysis of BST shows that, on average, the insert, delete and search takes for nodes. In the worst case, they degrade to that of a singly linked list: . To address the boundless increase of the tree height with arbitrary insertions and deletions, self-balancing variants of BSTs are introduced to bound the worst lookup complexity to that of the binary logarithm. AVL trees were the first self-balancing binary search trees, invented in 1962 by Georgy Adelson-Velsky and Evgenii Landis.



Binary search trees can be used to implement abstract data types such as dynamic sets, lookup tables and priority queues, and used in sorting algorithms such as tree sort.
YouTube Encyclopedic
-
1/5Views:1 169 17274 63576 953670 901112 027
-
Data structures: Binary Search Tree
-
Binary Search Trees (BST) Explained in Animated Demo
-
Binary Search Tree
-
5.10 Binary Search Trees (BST) - Insertion and Deletion Explained
-
Binary Tree Part 1 | BST | Binary Search Tree - Data Structures & Algorithms Tutorials In Python #10
Transcription
In our previous lesson, we talked about binary trees in general. Now, in this lesson we are going to talk about binary search tree, a special kind of binary tree which is an efficient structure to organize data for quick search as well as quick update. But before I start talking about binary search tree, I want you to think of a problem. What data structure will you use to store a modifiable collection? So, lets say you have a collection and it can be a collection of any data type, records in the collection can be of any type. Now, you want to store this collection in computers memory in some structure and then you want to be able to quickly search for a record in the collection and you also want to be able to modify the collection. You want to be able to insert an element in the collection or remove an element from the collection. So, what data structure will you use? Well, you can use an array or a linked list. These are two well known data structure in which we can store a collection. Now, what will be running time of these operations - search, insertion or removal, If we will use an array or a linked list. Lets first talk about arrays and for sale of simplicity, lets say we want to store integers. To store a modifiable list or collection of integers, we can create a large enough array and we can store the records in some part of the array. We can keep the end of the list marked. In this array that I am showing here, we have integers from 0 till 3. We have records from 0 till 3 and rest of the array is available space. Now to search some X in the collection, we will have to scan the array from index 0 till end and in worst case, we may have to look at all the elements in the list. If n is the number of elements in the list, time taken will be proportional to n or in other words, we can say that time complexity will be big-oh of n. Ok, now what will be the cost of insertion. Lets say we want to insert number 5 in this list. So, if there is some available space, all the cells in yellow are available, we can add one more cell by incrementing this marker 'end' and fill in the integer to be added. Time taken for this operation will be constant. Running time will not depend upon number of elements in the collection. So, we can say that time complexity will be big-oh of 1. Ok, now what about removal. Lets say we want to remove 1 from the collection. What we'll have to do is, we'll have to shift all records to the right of one by one position to the left and then we can decrement end. The cost of removal once again will be big-oh of n. In worst case, we will have to shift n-1 elements. Here, the cost of insertion will be big-oh of 1, if the array will have some available space. So, the array has to be large enough. If the array gets filled, what we can do is, we can create a new larger array, typically we create an array twice the size of the filled up array. So, we can create a new larger array and then we can copy the content of the filled up array into this new larger array. The copy operation will cost us big-oh of n. We have discussed this idea of dynamic array quite a bit in our previous lessons. So, insertion will be big-oh of 1 if array is not filled up and it will be big-oh of n if array is filled up. For now, lets just assume that the array will always be large enough. Lets now discuss the cost of these operations if we will use a linked list. If we would use a linked list, I have drawn a linked list of integers here, data type can be anything, the cost of search operation once again will be big-oh of n where n is number of records in the collection or number of nodes in the linked list. To search, in worst case, we will have to traverse the whole list. We will have to look at all the nodes. The cost of insertion in a linked list is big-oh of 1 at head and its big-oh of n at tail. We can choose to insert at head to keep the cost low. So, running time of insertion, we can say is big-oh of 1 or in other words, we will take constant time. Removal once again will be big-oh of n. We will first have to traverse the linked list and search the record and in worst case, we may have to look at all the nodes. Ok, so this is the cost of operations if we are going to use array or linked list. Insertion definitely is fast. But, how good is big-oh of n for an operation like search. What do you think? if we are searching for a record X, then in the worst case, we will have to compare this record X with all the n records in the collection. Lets say, our machine can perform a million comparisons in one second. So, we can say that machine can perform 10 the power 6 comparisons in one second. So, cost of one comparison will be 10 to the power -6 second. Machines in today's world deal with really large data. Its very much possible for real world data to have 100 million records or billion records. A lot of countries in this world have population more than 100 million. 2 countries have more than a billion people living in them. If we will have data about all the people living in a country, then it can easily be 100 million records. Ok, so if we are saying that the cost of 1 comparison is 10 the power -6 second. If n will be 100 million, time taken will be 100 seconds. 100 seconds for a search is not reasonable and search may be a frequently performed operation. Can we do something better? Can we do better than big-oh of n. Well, in an array, we can perform binary search if its sorted and the running time of binary search is big-oh of log n which is the best running time to have. I have drawn this array of integers here. Records in the array are sorted. Here the data type is integer. For some other data type, for some complex data type, we should be able to sort the collection based on some property or some key of the records. We should be able to compare the keys of records and the comparison logic will be different for different data types. For a collection of strings, for example, we may want to have the records sorted in dictionary or lexicographical order. So, we will compare and see which string will come first in dictionary order. Now this is the requirement that we have for binary search. The data structure should be an array and the records must be sorted. Ok, so the cost of search operation can be minimized if we will use a sorted array. But, in insertion or removal, we will have to make sure that the array is sorted afterwards. In this array, if I want to insert number 5 at this stage, i can't simply put 5 at index 6. what I'll have to do is, I'll first have to find the position at which I can insert 5 in the sorted list. We can find the position in order of log n time using binary search. We can perform a binary search to find the first integer greater than 5 in the list. So, we can find the position quickly. In this case, its index 2. But then, we will have to shift all the records starting this position one position to the right. And now, I can insert 5. So, even though we can find the position at which a record should be inserted quickly in big-oh of log n, this shifting in worst case will cost us big-oh of n. So, the running time overall for an insertion will be big-oh of n and similarly, the cost of removal will also be big-oh of n. We will have to shift some records. Ok, so when we are using sorted array, cost of search operation is minimized. In binary search for n records, we will have at max log n to the base 2 comparisons. So, if we can perform million comparisons in a second, then for n equal 2 to the power 31 which is greater than 2 billion, we are going to take only 31 micro-seconds. log of 2 to the power 31 to base 2 will be 31. Ok, we are fine with search now. we will be good for any practical value of n. But what about insertion and removal. They are still big-oh of n. Can we do something better here? Well, if we will use this data structure called binary search tree, I am writing it in short - BST for binary search tree, then the cost of all these 3 operations can be big-oh of log n in average case. The cost of all the operations will be big-oh of n in worst case. But we can avoid the worst case by making sure that the tree is always balanced. We had talked about balanced binary tree in our previous lesson. Binary search tree is only a special kind of binary tree. To make sure that the cost of these operations is always big-oh of log n, we should keep the binary search tree balanced. We'll talk about this in detail later. Let's first see what a binary search tree is and how cost of these operations is minimized when we use a binary search tree. Binary search tree is a binary tree in which for each node, value of all the nodes in left sub-tree is lesser and value of all the nodes in right sub-tree is greater. I have drawn binary tree as a recursive structure here. As we know, in a binary tree, each node can have at most 2 children. We can call one of the children left child. If we will look at the tree as recursive structure, left child will be the root of left sub-tree and similarly, right child will be the root of right sub-tree. Now, for a binary tree to be called binary search tree, value of all the nodes in left sub-tree must be lesser or we can say lesser or equal to handle duplicates and the value of all the nodes in right sub-tree must be greater and this must be true for all the nodes. So, in this recursive structure here, both left and right sub-trees must also be binary search trees. I'll draw a binary search tree of integers. Now, I have drawn a binary search tree of integers here. Lets see whether this property that for each node value of all the nodes in left subtree is lesser or equal and the value of all the nodes in right sub-tree must be greater is true or not. Lets first look at the root node. Nodes in the left subtree have values 10, 8 and 12. So, they are all lesser than15 and in right subtree, we have 17, 20 and 25, they are all greater than 15. So, we are good for the root node. Now, lets look at this node with value 10. In left, we have 8 which is lesser. In right, we have 12 which is greater. So, we are good. We are good for this node too having value 20 and we don't need to bother about leave nodes because they do not have children. So, this is a binary search tree. Now, what if I change this value 12 to 16. Now, is this still a binary search tree. Well, for node with value 10, we are good. The node with value 16 is in its right. So, not a problem. But for the root node, we have a node in left sub-tree with higher value now. So, this tree is not a binary search tree. I'll revert back and make the value 12 again. Now, as we were saying we can search, insert or delete in a binary search tree in big-oh of log n time in average case. How is it really possible? Lets first talk about search. If these integers that I have here in the tree were in a sorted array, we could have performed binary search and what do we do in binary search. Lets say we want to search number 10 in this array. What we do in binary search is, we first define the complete list as our search space. The number can exist only within the search space. I'll mark search space using these two pointers - start and end. Now, we compare the number to be searched or the element to be searched with mid element of the search space or the median. And if the record being searched, if the element being searched is lesser, we go searching in the left half, else we go searching in the right half. In case of equality, we have found the element. In this case, 10 is lesser than 15. So, we will go searching towards left. Our search space is reduced now to half. Once again, we will compare to the mid-element and bingo, this time, we have got a match. In binary search, we start with n elements in search space and then if mid element is not the element that we are looking for, we reduce the search space to n/2 and we go on reducing the search space to half, till we either find the record that we are looking for or we get to only one element in search space and be done. In this whole reduction, if we will go from n to n/2 to n/4 to n/8 and so on, we will have log n to the base 2 steps. If we are taking k steps, then n upon 2 to the power k will be equal to 1 which will imply 2 to the power k will be equal to n and k will be equal to log n to the base 2. So, this is why running time of binary search is big-oh of log n. Now, if we will use this binary search tree to store the integers, search operation will be very similar. Lets say, we want to search for number 12. What we'll do is, we start at root and then we will compare the value to be searched, the integer to be searched with value of the root. if its equal, we are done with the search, if its lesser, we know that we need to go to the left sub-tree because in a binary search tree, all the elements in left sub-tree are lesser and all the elements in right sub-tree are greater. Now, we will go and look at the left child of node with value 15. We know that number 12 that we are looking for can exist in this sub-tree only and anything apart from the sub-tree is discarded. So, we have reduced the search space to only these 3 nodes having value 10, 8 and 12. Now, once again, we will compare 12 with 10. We are not equal. 12 is greater, so we know that we need to go looking in right sub-tree of this node with value 10. So, now our search space is reduced to just one node. Once again, we will compare the value here at this node and we have a match. So, searching an element in binary search tree is basically this traversal in which at each step, we will go either towards left or right and hence at each step, we will discard one of the sub-trees. if the tree is balanced, we call a tree balanced if for all nodes, the difference between the heights of left and right sub-trees is not greater than 1. So, if the tree is balanced, we will start with a search space of n nodes and when we will discard one of the sub-trees, we will discard n/2 nodes. So, our search space will be reduced to n/2 and then in next step, we will reduce the search space to n/4. We will go on reducing like this till we find the element or till our search space is reduced to only one node when we will be done. So, the search here is also a binary search. And that's why the name - Binary Search Tree. This tree that I am showing here is balanced. In fact this is a perfect binary tree. But with same records, we can have an unbalanced tree like this. This tree has got the same integer values as we had in the previous structure and this is also a binary search tree, but this is unbalanced. This is as good as a linked list. In this tree there is no right sub-tree for any of the nodes. Search space will be reduced by only one.at each step. From n nodes in search space, we will go to n-1 nodes and then to n-2 nodes, all the way till 1 will be n steps. In binary search tree, in average case, cost of search, insertion or deletion is big-oh of log n and in worst case, this is the worst case arrangement that I am showing you. The running time will be big-oh of n. We always try to avoid the worst case by trying to keep the binary search tree balanced. With same records in the tree, there can be multiple possible arrangements. For these integers in this tree, another arrangement is this. For all the nodes, we have nothing to discard in left sub-tree in a search. This is another arrangement. This is still balanced because for all the nodes, the difference between the heights of left and right sub-tree is not greater than 1. But this is the best arrangement when we have a perfect binary tree. At each step, we will have exactly n/2 nodes to discard. Ok, now to insert some records in binary search tree, we will first have to find the position at which we can insert and we can find the position in big-oh of log n time. Lets say we want to insert 19 in this tree, what we will do is start at the root. If the value to be inserted is lesser or equal, if there is no child, insert as left child or go left. If the value is greater and there is no right child, insert as right child or go right. In this case, 19 is greater, so we will go right. Now, we are at 20. 19 is lesser and left sub-tree is not empty. We have a left child. So, we will go left. Now, we are at 17, 19 is greater than 17. So, it should go in right of 17. There is no right child of 17. So, we will create a node with value 19 and link it to this node with value 17 as right child. Because we are using pointers or references here just like linked list, no shifting is needed like an array. Creating a link will take constant time. So, overall insertion will also cost us like search. To delete also, we will first have to search the node. Search once again will be big-oh of log n and deleting the node will only mean adjusting some links. So, removal also is going to be like search - big-oh of log n in average case. Binary search tree gets unbalanced during insertion and deletion. So, often during insertion and deletion, we restore the balancing. There are ways to do it and we will talk about all of this in detail in later lessons. In next lesson, we will discuss implementation of binary search tree in detail. This is it for this lesson. Thanks for watching.
History
The binary search tree algorithm was discovered independently by several researchers, including P.F. Windley, Andrew Donald Booth, Andrew Colin, Thomas N. Hibbard.[1][2] The algorithm is attributed to Conway Berners-Lee and David Wheeler, who used it for storing labeled data in magnetic tapes in 1960.[3] One of the earliest and popular binary search tree algorithm is that of Hibbard.[1]
The time complexities of a binary search tree increases boundlessly with the tree height if the nodes are inserted in an arbitrary order, therefore self-balancing binary search trees were introduced to bound the height of the tree to .[4] Various height-balanced binary search trees were introduced to confine the tree height, such as AVL trees, Treaps, and red–black trees.[5]
The AVL tree was invented by Georgy Adelson-Velsky and Evgenii Landis in 1962 for the efficient organization of information.[6][7] It was the first self-balancing binary search tree to be invented.[8]
Overview
A binary search tree is a rooted binary tree in which nodes are arranged in strict total order in which the nodes with keys greater than any particular node A is stored on the right sub-trees to that node A and the nodes with keys equal to or less than A are stored on the left sub-trees to A, satisfying the binary search property.[9]: 298 [10]: 287
Binary search trees are also efficacious in sortings and search algorithms. However, the search complexity of a BST depends upon the order in which the nodes are inserted and deleted; since in worst case, successive operations in the binary search tree may lead to degeneracy and form a singly linked list (or "unbalanced tree") like structure, thus has the same worst-case complexity as a linked list.[11][9]: 299-302
Binary search trees are also a fundamental data structure used in construction of abstract data structures such as sets, multisets, and associative arrays.
Operations
Searching
Searching in a binary search tree for a specific key can be programmed recursively or iteratively.
Searching begins by examining the root node. If the tree is nil, the key being searched for does not exist in the tree. Otherwise, if the key equals that of the root, the search is successful and the node is returned. If the key is less than that of the root, the search proceeds by examining the left subtree. Similarly, if the key is greater than that of the root, the search proceeds by examining the right subtree. This process is repeated until the key is found or the remaining subtree is . If the searched key is not found after a subtree is reached, then the key is not present in the tree.[10]: 290–291

Recursive search
The following pseudocode implements the BST search procedure through recursion.[10]: 290
Recursive-Tree-Search(x, key)
if x = NIL or key = x.key then
return x
if key < x.key then
return Recursive-Tree-Search(x.left, key)
else
return Recursive-Tree-Search(x.right, key)
end if
|
The recursive procedure continues until a or the being searched for are encountered.

Iterative search
The recursive version of the search can be "unrolled" into a while loop. On most machines, the iterative version is found to be more efficient.[10]: 291
Iterative-Tree-Search(x, key)
while x ≠ NIL and key ≠ x.key do
if key < x.key then
x := x.left
else
x := x.right
end if
repeat
return x
|
Since the search may proceed till some leaf node, the running time complexity of BST search is where is the height of the tree. However, the worst case for BST search is where is the total number of nodes in the BST, because an unbalanced BST may degenerate to a linked list. However, if the BST is height-balanced the height is .[10]: 290


Successor and predecessor
For certain operations, given a node , finding the successor or predecessor of is crucial. Assuming all the keys of a BST are distinct, the successor of a node in a BST is the node with the smallest key greater than 's key. On the other hand, the predecessor of a node in a BST is the node with the largest key smaller than 's key. The following pseudocode finds the successor and predecessor of a node in a BST.[12][13][10]: 292–293

BST-Successor(x)
if x.right ≠ NIL then
return BST-Minimum(x.right)
end if
y := x.parent
while y ≠ NIL and x = y.right do
x := y
y := y.parent
repeat
return y
|
BST-Predecessor(x)
if x.left ≠ NIL then
return BST-Maximum(x.left)
end if
y := x.parent
while y ≠ NIL and x = y.left do
x := y
y := y.parent
repeat
return y
|
Operations such as finding a node in a BST whose key is the maximum or minimum are critical in certain operations, such as determining the successor and predecessor of nodes. Following is the pseudocode for the operations.[10]: 291–292
BST-Maximum(x)
while x.right ≠ NIL do
x := x.right
repeat
return x
|
BST-Minimum(x)
while x.left ≠ NIL do
x := x.left
repeat
return x
|
Insertion
Operations such as insertion and deletion cause the BST representation to change dynamically. The data structure must be modified in such a way that the properties of BST continue to hold. New nodes are inserted as leaf nodes in the BST.[10]: 294–295 Following is an iterative implementation of the insertion operation.[10]: 294
1 BST-Insert(T, z) 2 y := NIL 3 x := T.root 4 while x ≠ NIL do 5 y := x 6 if z.key < x.key then 7 x := x.left 8 else 9 x := x.right 10 end if 11 repeat 12 z.parent := y 13 if y = NIL then 14 T.root := z 15 else if z.key < y.key then 16 y.left := z 17 else 18 y.right := z 19 end if |
The procedure maintains a "trailing pointer" as a parent of . After initialization on line 2, the while loop along lines 4-11 causes the pointers to be updated. If is , the BST is empty, thus is inserted as the root node of the binary search tree , if it is not , insertion proceeds by comparing the keys to that of on the lines 15-19 and the node is inserted accordingly.[10]: 295



Deletion


The deletion of a node, say , from the binary search tree has three cases:[10]: 295-297


- If is a leaf node, the parent node of gets replaced by and consequently is removed from the , as shown in (a).
- If has only one child, the child node of gets elevated by modifying the parent node of to point to the child node, consequently taking 's position in the tree, as shown in (b) and (c).
- If has both left and right children, the successor of , say , displaces by following the two cases:
- If is 's right child, as shown in (d), displaces and 's right child remain unchanged.
- If lies within 's right subtree but is not 's right child, as shown in (e), first gets replaced by its own right child, and then it displaces 's position in the tree.


The following pseudocode implements the deletion operation in a binary search tree.[10]: 296-298
1 BST-Delete(BST, D) 2 if D.left = NIL then 3 Shift-Nodes(BST, D, D.right) 4 else if D.right = NIL then 5 Shift-Nodes(BST, D, D.left) 6 else 7 E := BST-Successor(D) 8 if E.parent ≠ D then 9 Shift-Nodes(BST, E, E.right) 10 E.right := D.right 11 E.right.parent := E 12 end if 13 Shift-Nodes(BST, D, E) 14 E.left := D.left 15 E.left.parent := E 16 end if |
1 Shift-Nodes(BST, u, v) 2 if u.parent = NIL then 3 BST.root := v 4 else if u = u.parent.left then 5 u.parent.left := v 5 else 6 u.parent.right := v 7 end if 8 if v ≠ NIL then 9 v.parent := u.parent 10 end if |
The procedure deals with the 3 special cases mentioned above. Lines 2-3 deal with case 1; lines 4-5 deal with case 2 and lines 6-16 for case 3. The helper function is used within the deletion algorithm for the purpose of replacing the node with in the binary search tree .[10]: 298 This procedure handles the deletion (and substitution) of from .




Traversal
A BST can be traversed through three basic algorithms: inorder, preorder, and postorder tree walks.[10]: 287
- Inorder tree walk: Nodes from the left subtree get visited first, followed by the root node and right subtree. Such a traversal visits all the nodes in the order of non-decreasing key sequence.
- Preorder tree walk: The root node gets visited first, followed by left and right subtrees.
- Postorder tree walk: Nodes from the left subtree get visited first, followed by the right subtree, and finally, the root.
Following is a recursive implementation of the tree walks.[10]: 287–289
Inorder-Tree-Walk(x)
if x ≠ NIL then
Inorder-Tree-Walk(x.left)
visit node
Inorder-Tree-Walk(x.right)
end if
|
Preorder-Tree-Walk(x)
if x ≠ NIL then
visit node
Preorder-Tree-Walk(x.left)
Preorder-Tree-Walk(x.right)
end if
|
Postorder-Tree-Walk(x)
if x ≠ NIL then
Postorder-Tree-Walk(x.left)
Postorder-Tree-Walk(x.right)
visit node
end if
|
Balanced binary search trees
Without rebalancing, insertions or deletions in a binary search tree may lead to degeneration, resulting in a height of the tree (where is number of items in a tree), so that the lookup performance is deteriorated to that of a linear search.[14] Keeping the search tree balanced and height bounded by is a key to the usefulness of the binary search tree. This can be achieved by "self-balancing" mechanisms during the updation operations to the tree designed to maintain the tree height to the binary logarithmic complexity.[4][15]: 50
Height-balanced trees
A tree is height-balanced if the heights of the left sub-tree and right sub-tree are guaranteed to be related by a constant factor. This property was introduced by the AVL tree and continued by the red–black tree.[15]: 50–51 The heights of all the nodes on the path from the root to the modified leaf node have to be observed and possibly corrected on every insert and delete operation to the tree.[15]: 52
Weight-balanced trees
In a weight-balanced tree, the criterion of a balanced tree is the number of leaves of the subtrees. The weights of the left and right subtrees differ at most by .[16][15]: 61 However, the difference is bound by a ratio of the weights, since a strong balance condition of cannot be maintained with rebalancing work during insert and delete operations. The -weight-balanced trees gives an entire family of balance conditions, where each left and right subtrees have each at least a fraction of of the total weight of the subtree.[15]: 62


Types
There are several self-balanced binary search trees, including T-tree,[17] treap,[18] red-black tree,[19] B-tree,[20] 2–3 tree,[21] and Splay tree.[22]
Examples of applications
Sort
Binary search trees are used in sorting algorithms such as tree sort, where all the elements are inserted at once and the tree is traversed at an in-order fashion.[23] BSTs are also used in quicksort.[24]
Priority queue operations
Binary search trees are used in implementing priority queues, using the node's key as priorities. Adding new elements to the queue follows the regular BST insertion operation but the removal operation depends on the type of priority queue:[25]
- If it is an ascending order priority queue, removal of an element with the lowest priority is done through leftward traversal of the BST.
- If it is a descending order priority queue, removal of an element with the highest priority is done through rightward traversal of the BST.
See also
References
- ^ a b Culberson, J.; Munro, J. I. (1 January 1989). "Explaining the Behaviour of Binary Search Trees Under Prolonged Updates: A Model and Simulations". The Computer Journal. 32 (1): 68–69. doi:10.1093/comjnl/32.1.68.
- ^ Culberson, J.; Munro, J. I. (28 July 1986). "Analysis of the standard deletion algorithms in exact fit domain binary search trees". Algorithmica. 5 (1–4). Springer Publishing, University of Waterloo: 297. doi:10.1007/BF01840390. S2CID 971813.
- ^ P. F. Windley (1 January 1960). "Trees, Forests and Rearranging". The Computer Journal. 3 (2): 84. doi:10.1093/comjnl/3.2.84.
- ^ a b Knuth, Donald (1998). "Section 6.2.3: Balanced Trees". The Art of Computer Programming (PDF). Vol. 3 (2 ed.). Addison-Wesley. pp. 458–481. ISBN 978-0201896855. Archived (PDF) from the original on 2022-10-09.
- ^ Paul E. Black, "red-black tree", in Dictionary of Algorithms and Data Structures [online], Paul E. Black, ed. 12 November 2019. (accessed May 19 2022) from: https://www.nist.gov/dads/HTML/redblack.html
- ^ Myers, Andrew. "CS 312 Lecture: AVL Trees". Cornell University, Department of Computer Science. Archived from the original on 27 April 2021. Retrieved 19 May 2022.
- ^ Adelson-Velsky, Georgy; Landis, Evgenii (1962). "An algorithm for the organization of information". Proceedings of the USSR Academy of Sciences (in Russian). 146: 263–266. English translation by Myron J. Ricci in Soviet Mathematics - Doklady, 3:1259–1263, 1962.
- ^ Pitassi, Toniann (2015). "CSC263: Balanced BSTs, AVL tree" (PDF). University of Toronto, Department of Computer Science. p. 6. Archived (PDF) from the original on 14 February 2019. Retrieved 19 May 2022.
- ^ a b Thareja, Reema (13 October 2018). "Hashing and Collision". Data Structures Using C (2 ed.). Oxford University Press. ISBN 9780198099307.
- ^ a b c d e f g h i j k l m n o Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). Introduction to Algorithms (2nd ed.). MIT Press. ISBN 0-262-03293-7.
- ^ R. A. Frost; M. M. Peterson (1 February 1982). "A Short Note on Binary Search Trees". The Computer Journal. 25 (1). Oxford University Press: 158. doi:10.1093/comjnl/25.1.158.
- ^ Junzhou Huang. "Design and Analysis of Algorithms" (PDF). University of Texas at Arlington. p. 12. Archived (PDF) from the original on 13 April 2021. Retrieved 17 May 2021.
- ^ Ray, Ray. "Binary Search Tree". Loyola Marymount University, Department of Computer Science. Retrieved 17 May 2022.
- ^ Thornton, Alex (2021). "ICS 46: Binary Search Trees". University of California, Irvine. Archived from the original on 4 July 2021. Retrieved 21 October 2021.
- ^ a b c d e Brass, Peter (January 2011). Advanced Data Structure. Cambridge University Press. doi:10.1017/CBO9780511800191. ISBN 9780511800191.
- ^ Blum, Norbert; Mehlhorn, Kurt (1978). "On the Average Number of Rebalancing Operations in Weight-Balanced Trees" (PDF). Theoretical Computer Science. 11 (3): 303–320. doi:10.1016/0304-3975(80)90018-3. Archived (PDF) from the original on 2022-10-09.
- ^ Lehman, Tobin J.; Carey, Michael J. (25–28 August 1986). A Study of Index Structures for Main Memory Database Management Systems. Twelfth International Conference on Very Large Databases (VLDB 1986). Kyoto. ISBN 0-934613-18-4.
- ^ Aragon, Cecilia R.; Seidel, Raimund (1989), "Randomized Search Trees" (PDF), 30th Annual Symposium on Foundations of Computer Science, Washington, D.C.: IEEE Computer Society Press, pp. 540–545, doi:10.1109/SFCS.1989.63531, ISBN 0-8186-1982-1, archived (PDF) from the original on 2022-10-09
- ^ Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). "Red–Black Trees". Introduction to Algorithms (second ed.). MIT Press. pp. 273–301. ISBN 978-0-262-03293-3.
- ^ Comer, Douglas (June 1979), "The Ubiquitous B-Tree", Computing Surveys, 11 (2): 123–137, doi:10.1145/356770.356776, ISSN 0360-0300, S2CID 101673
- ^ Knuth, Donald M (1998). "6.2.4". The Art of Computer Programming. Vol. 3 (2 ed.). Addison Wesley. ISBN 9780201896855.
The 2–3 trees defined at the close of Section 6.2.3 are equivalent to B-Trees of order 3.
- ^ Sleator, Daniel D.; Tarjan, Robert E. (1985). "Self-Adjusting Binary Search Trees" (PDF). Journal of the ACM. 32 (3): 652–686. doi:10.1145/3828.3835. S2CID 1165848.
- ^ Narayanan, Arvind (2019). "COS226: Binary search trees". Princeton University School of Engineering and Applied Science. Archived from the original on 22 March 2021. Retrieved 21 October 2021 – via cs.princeton.edu.
- ^ Xiong, Li. "A Connection Between Binary Search Trees and Quicksort". Oxford College of Emory University, The Department of Mathematics and Computer Science. Archived from the original on 26 February 2021. Retrieved 4 June 2022.
- ^ Myers, Andrew. "CS 2112 Lecture and Recitation Notes: Priority Queues and Heaps". Cornell University, Department of Computer Science. Archived from the original on 21 October 2021. Retrieved 21 October 2021.
Further reading
 This article incorporates public domain material from Paul E. Black. "Binary Search Tree". Dictionary of Algorithms and Data Structures. NIST.
This article incorporates public domain material from Paul E. Black. "Binary Search Tree". Dictionary of Algorithms and Data Structures. NIST.- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). "12: Binary search trees, 15.5: Optimal binary search trees". Introduction to Algorithms (2nd ed.). MIT Press. pp. 253–272, 356–363. ISBN 0-262-03293-7.
- Jarc, Duane J. (3 December 2005). "Binary Tree Traversals". Interactive Data Structure Visualizations. University of Maryland. Archived from the original on 27 February 2014. Retrieved 30 April 2006.
- Knuth, Donald (1997). "6.2.2: Binary Tree Searching". The Art of Computer Programming. Vol. 3: "Sorting and Searching" (3rd ed.). Addison-Wesley. pp. 426–458. ISBN 0-201-89685-0.
- Long, Sean. "Binary Search Tree" (PPT). Data Structures and Algorithms Visualization-A PowerPoint Slides Based Approach. SUNY Oneonta.
- Parlante, Nick (2001). "Binary Trees". CS Education Library. Stanford University. Archived from the original on 2022-01-30.
External links
- Ben Pfaff: An Introduction to Binary Search Trees and Balanced Trees. (PDF; 1675 kB) 2004.
- Binary Tree Visualizer (JavaScript animation of various BT-based data structures)